Memory Barrier / Memory Reorder / x86 TSO
上周拜读了一下 Perfbook 的 「Appendix C: Why Memory Barriers?」,这篇文章最早的版本应该是 2009 年 Paul E. McKenney 的 「Memory Barriers: A Hardware View for Software Hackers」(后续的版本有一些更新和删节),学习了 Store Buffer 和 Invalidate Queue。这里想结合一下 C++ 中提供的 Memory Order 和 x86 内存模型,记录一些理解 / 问题 / 思考。
Store Buffer 和 Memory Barrier
Store Buffer 是为了解决 Store 等待的问题,原文中的用词是 Unnecessary Stall,意思是:根据 MESI 协议,如果要对一个 CPU 核要对一个变量执行 Store 操作,必须让这个变量在其他核心上先失效(Invalidate);即发送一个 Invalidate 请求,并且等待其他核回复 Invalidate ACK,才能完成 Store 操作。如图所示,中间存在一个等待缓存同步的时间,这个时间是不必要的等待。
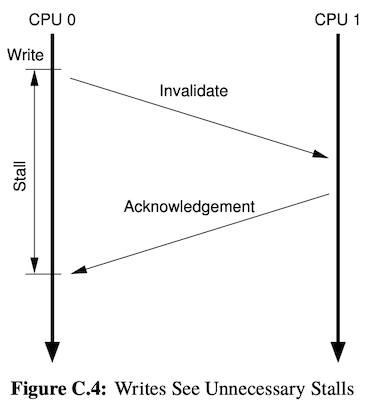
Store Buffer 的本质就是异步化了 Invalidate ACK 的等待。 当遇到 Store 操作时,CPU 可以先把 Store 操作放回 Store Buffer 中,然后继续执行后续的指令。于是前一个 Store 指令还没有生效,就开始执行后续的指令了,这样避免了不必要的等待,但是造成了 内存乱序。
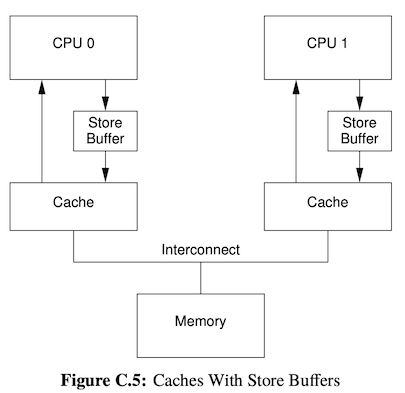
内存乱序 导致了这个 Store 操作的结果对后续的操作是不可见的。一些情况下,我们允许这个 不可见 发生,如果后续的操作并不在乎这个 Store 操作的结果。但是有一些情况下,我们不希望它不可见,为了解决可见性的问题,有了:
- Store Forwarding: 它解决当前核访问 Store 的结果的可见性,即「我看我自己」。思路很简单,就是 CPU 访问变量的时候,除了查看缓存 / 内存,还会查看一下 Store Buffer。
- Memory Barrier / 内存屏障: 它解决跨核访问 Store
的结果的可见性,即「别人看我」或者「我看别人」。思路是:如果希望这个在
Store Buffer 中的 Store
操作的结果对其他核可见,那么我们必须等待它被刷入缓存,即在这种特殊情况下我们希望有一个
Stall。
smp_mb()可以等待 Store Buffer 排空,保证之前的 Store 操作对其他核可见。(当然它也可以等待 Invalidate Queue 排空,如果只希望等待 Store Buffer 排空,可以用smp_wmb()。)
由此可见,缓存是一个「充满阳光的广场」,而 Store Buffer 是一个「充满阴影的角落」。发生在缓存里的事情是透明的,发生在 Store Buffer 里的事情是不可见的;如果希望它可见,就必须等待它被刷入缓存。
假设 a / b
的读写在硬件层面都是原子的,即我们只考虑内存顺序,不考虑数据竞争导致的撕裂。(下文同)
看这样一个例子:
1 | // Initial state: |
如果不加这个 smp_mb(),很可能 CPU 1 先看到
b = 1 的结果,但是看不到 a = 1 的结果,因为对
a 的修改还在 CPU 0 的 Store Buffer
中,还没有被刷入缓存,导致 assert(a == 1) 失败。
Invalidate Queue 和 Memory Barrier
Invalidate Queue 是为了解决 Invalidate ACK 等待的问题,它常常事作为 Store 等待的 「下半场」。
根据 MESI,如果要对一个变量做 Store 操作并且当前的核不独占这个变量,把操作塞进 Store Buffer 的同时还需要向外部发送 Invalidate 请求,等待其他核回复 Invalidate ACK,才能完成 Store 操作。在其他的核收到 Invalidate 请求到处理完成之间,存在一个等待时间;也就是如果收到 Invalidate 到发送 Invalidate ACK 之间是同步执行的,那么就会有一个不必要的等待。
Invalidate Queue 的作用就是把 Invalidate 处理的等待异步化了。
当一个核收到 Invalidate 请求时,它会把这个请求放入 Invalidate Queue 中,然后立即回复 Invalidate ACK,欺骗发起 Invalidate 请求的核,让它以为自己已经收到了 Invalidate ACK,继续执行后续的指令;而实际上这个 Invalidate 请求还没有被处理完成,Invalidate Queue 中还有这个请求在等待处理。
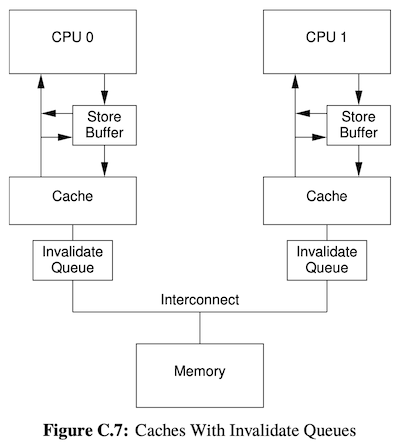
因此,Invalidate Queue 也会导致 内存乱序。如果 CPU 0
发起 Store a = 1 操作,并给 CPU 1 发送 Invalidate 请求,CPU
1 欺骗 CPU 0 之后,CPU 0 收到 ACK 会把 Store 的结果刷入缓存并且改成
Modified 状态;但是此时 CPU 1 的缓存里仍然是 a 的旧值。
如果我们用 CPU 1 读
a,那我们就不关心这个乱序。但是如果我们用 CPU 1 读
a,那么就不能观测到 Store 最新的结果。
为了解决这个问题,我们需要在 CPU 1 读 a 之前加一个
Memory Barrier(smp_mb() 或者
smp_rmb()),等待 Invalidate Queue 排空,保证之前的
Invalidate 请求被处理完成了,这样 CPU 1 才能看到 Store 的最新结果。
看这样一段代码:
1 | // Initial state: |
如果 bar 不加这个 smp_mb(),很可能 CPU 1
先看到 b = 1 的结果,但是看不到 a = 1
的结果。此时 CPU 1 只能看到 a
的旧值,导致断言失败。于是乎这里排空 Invalidate Queue 就很重要,让 CPU 1
中的 a 失效,CPU 1 才能重新发起 Read 请求,看到
a = 1 的结果。
Read / Write Memory Barrier
1 | // Runs on CPU 0 |
smp_mb() 是一个全屏障,等待 Store Buffer 和 Invalidate
Queue 都排空了,继续执行下面的代码。
写屏障: 这段代码中,foo 中的
smp_mb() 其实只关心 Store Buffer,不关心 Invalidate
Queue。关心 Store Buffer 是因为希望 a = 1
的结果对其他核可见;不关心 Invalidate Queue
是因为后面并没有读取其他核最近修改的变量。此时 smp_wmb()
就足够了,它只管等待 Store Buffer 排空。
读屏障: 而 bar 中的
smp_mb() 其实只关心 Invalidate Queue,不关心 Store
Buffer。关心 Invalidate Queue 是因为希望看到其他核的最新修改;不关心
Store Buffer
是因为自己没有写操作,也不可能希望别人看到自己的某个写操作的结果。此时
smp_rmb() 就足够了,它只管等待 Invalidate Queue 排空。
即如下的代码。
1 | // Runs on CPU 0 |
Program Order / Visibility Order
由此可以看出 Invalidate Queue 会导致 Load-Load 乱序,这里的 Load-Load
乱序是指:在上面的例子中,如果 CPU 1 先读 b,然后读
a,那么就可能先看到 b = 1 的结果,但是看不到
a = 1 的结果,就好像读 a 在读 b
之前发生一样;这两个 Load
操作在同一个线程上,但是我们观测到的执行顺序和代码中的顺序不一样。
在 Store Buffer 的例子中, 我们看到了 Store-Store 乱序,如果 CPU 0
先写 a,然后写 b,那么就可能先看到
b = 1 的结果,但是看不到 a = 1
的结果,就好像写 b 在写 a
之前发生一样;这两个 Store
操作在同一个线程上,但是我们观测到的执行顺序和代码中的顺序不一样。
实际上,代码 「开始执行」 的顺序是一样的,严格遵循代码中的顺序;但是代码 「执行生效」 的顺序可能不一样,可能会出现乱序的情况。我们观测到的执行顺序是 「执行生效」 的顺序,而不是 「开始执行」 的顺序,即 Program Order / Execution Order(开始执行的顺序)不等于 Visibility Order(最终生效的顺序)。
除了这两种乱序,还有 Store-Load 和 Load-Store,他们的成因分别是:
| 乱序类型 | 物理诱因 (Primary Cause) | 核心本质 |
|---|---|---|
| Store-Store | Store Buffer | “写操作”之间异步竞争导致的可见性乱序 |
| Store-Load | Store Buffer | “写”还没出家门,“读”就已经完成了 |
| Load-Load | Invalidate Queue | “读”到了本该消失的旧数据(由于失效延迟) |
| Load-Store | 预测执行 / 弱内存模型 | 读操作还没确认,写操作就提前跑了 |
由此可见 Store Buffer 主要导致涉及写的乱序,因为写操作被异步化了,它对外部生效的时刻就被推迟了;而 Invalidate Queue 主要导致涉及读的乱序,它让本应该失效的缓存行延迟失效。
一个特殊的情况是 Load-Store,它在 x86
这样的强内存模型上是不可能发生的,但是在 ARM
这样的弱内存模型上很常见,例如微架构预测执行(Speculative
Execution)会让它发生:假设 Load A; Store B;,Load A
因为缓存缺失(Cache Miss)卡住了,CPU 核心闲着也是闲着,它会往后看。CPU
预测 Load A 最终一定会完成,且不会影响 Store B
的地址,于是它越过还没完成的 Load A,提前把 Store B 给执行了(丢进了
Store Buffer)。
OS Memory Barrier vs. C++ Memory Order
smp_*
是操作系统内核视角下直接操纵硬件的独立内存屏障(Standalone Memory
Barrier);而 std::memory_order_* 是 C++
标准语言层面提供的“带有内存顺序语义的原子操作(Operations with Memory
Ordering semantics),他们有所不同。
上面我们看到的代码可以改写成:
1 | int a = 0; // a can be non-atomic. |
但是 smp_wmb 不等于
std::memory_order_release,smp_rmb 不等于
std::memory_order_acquire。
约束方式不同
总体上,约束方式的不同表现为:
| 管辖范围 | 防守方向 | |
|---|---|---|
smp_wmb |
只管写 | 双向 |
std::memory_order_release |
此前所有的读写操作 | 单向(蟑螂屋) |
smp_rmb |
只管读 | 双向 |
std::memory_order_acquire |
此后的所有读写操作 | 单向(蟑螂屋) |
smp_wmb只约束写操作,因为它只对 Store Buffer 划线,这条线之前所有的写操作必然在之后所有的写操作之前对外可见。std::memory_order_release约束此前的所有读写操作,不能排队到它的后面,这是它的语义。smp_rmb只约束读操作,因为它只清空 Invalidate Queue,这条线之后的操作才能绝对安全地读到最新的结果,这条线之前的可能是脏数据。std::memory_order_acquire约束此后的所有读写操作,不能排队到它的前面,这是它的语义。
范围:R / W vs. All
看这样一个写屏障 vs. release 的例子:
1 | int r = x; // Load |
对于前面的那个读操作
int r = x;,硬件完全可以把它重排到墙后面去,也就是变成先写
b = 1 再读 x。这堵墙对读操作是完全透明的。
如果使用 C++ 的 Release 语义:
1 | int r = x; // Load |
Release 表示这个 Store
之前所有的读写操作都不能排到它的后面。这意味着,不仅 a = 1
被死死按在 b.store 前面,连 int r = x;
这个读操作也被死死按在前面,绝不能漏到下面去。
再看一个读屏障的例子:
1 | int r1 = x; // Load |
对于后面的那个写操作
z = 1;,硬件完全可以把它重排到墙前面去,也就是变成先写
z = 1 再读
r1 = x。这在弱内存模型架构上是绝对合法的 Load-Store
乱序。
如果使用 C++ 的 Acquire 语义:
1 | int r1 = x; // Load |
这里 r3 = u 被约束在 Acquire 的后面,z = 1
也被约束在 Acquire 的后面。
小结:
smp_wmb()只管 Store-Store 不乱序;std::memory_order_release管 Load-Store、Store-Store 都不乱序(确保一切前置准备工作都做完)。smp_rmb()只管 Load-Load 不乱序;std::memory_order_acquire管 Load-Load、Load-Store 都不乱序(确保一切后续操作都在最新状态下执行)。
那如果要用 C++ Memory Order 管 Store-Load 不乱序呢?
只能用最重的
std::memory_order_seq_cst(顺序一致性)。
如果用 Acquire / Release 会发生什么呢?
1 | a.store(1, std::memory_order_release); // Store |
第一个 Store 保证上面的代码不准掉下来,第二个 Load
保证下面的代码不准往上跑。仔细看!如果这两个挨在一起,load(acquire)
是完全可以偷偷翻到 store(release)
上面去的!因为它们都没有禁止“对方”越过自己。
但是它们之间的 Store-Load 是不受约束的,可能会发生乱序。
要想保证 Store 绝对在 Load 之前发生,必须双方都使用
std::memory_order_seq_cst。这是 C++
内存模型里最强的屏障,它会在底层强制排空 Store Buffer。
那如果要用
smp_*管 Store-Load 不乱序呢?
必须上最重的全屏障 smp_mb()。
为什么 smp_wmb() 和 smp_rmb() 都不行?
smp_wmb()只在 Store Buffer 里画线,只卡后面的写,根本不管后面的读。smp_rmb()只清空 Invalidate Queue,只卡前面的读,根本不管前面的写。
只有 smp_mb() 能强迫 CPU
在执行读操作之前,先把前面那个写操作彻底写回 L1 Cache 并对全局可见。
那如果要用
smp_*管 Load-Store 不乱序呢?
全屏障 smp_mb() 依然可以搞定,但是这里和 Store Buffer /
Invalidate Queue 无关了。
例如:
1 | int r = data_buffer[index]; // 1. Load. |
这个情况极有可能发生,由于 Load 极慢(Cache Miss 要去主存取数据),而 Store 极快。
在这个例子中的内存屏障清空 Store Buffer 和 Invalidate Queue 都没有什么意义了,因为它们都不涉及 Load-Store 乱序了,因为:清空 Store Buffer / Invalidate Queue 只解决 Cache Coherence 相关的乱序,不解决核心乱序执行(Out-of-Order Execution) 导致的乱序!
此时 smp_mb() 化身成为
最严厉的流水线调度官。它对 CPU 内部的 Load / Store
Unit(访存队列)下达了命令:「所有在屏障前面的 Load
操作,必须在物理上拿到确切的数据(数据真正进入寄存器),并且指令正式退休(Retire)之后,屏障后面的所有
Store 操作,才被允许离开核心内部的 Store Queue,真正发往 Store Buffer 或
L1 Cache。」
所以 smp_mb() 是极其 昂贵 的。
于是使用 smp_mb() 来禁止 Load-Store
乱序,虽然是可行的,但代价太大了。Linux 内核的开发者发现 C++ 有 Acquire
这种高效的单向门(不仅防 Load-Load,也防
Load-Store),也引入了附着在变量上的原语:
1 | int r = smp_load_acquire(&a); // Load |
避坑指南
| 乱序类型 | 含义 | C++ 最优解 | Linux 内核最优解 |
|---|---|---|---|
| 写-写 (S-S) | 先写,后写 | release | smp_wmb() 或 smp_store_release() |
| 读-读 (L-L) | 先读,后读 | acquire | smp_rmb() 或 smp_load_acquire() |
| 读-写 (L-S) | 先读,后写 | acquire | smp_mb() 或 smp_load_acquire() |
| 写-读 (S-L) | 先写,后读 | seq_cst | smp_mb() |
核心口诀:同类读写用单向,写读顺序全屏障
- 遇到同类(写写 S-S、读读 L-L)或者读写(L-S),单向阀(acquire / release)和半屏障就能搞定,性能损失较小;
- 只要遇到写读(S-L),不要犹豫,直接上全屏障(seq_cst / smp_mb()),因为这是违背 CPU 缓存物理天性的极限操作。(CPU 天性:异步地写,同步地读)
方向:双向 vs. 单向
再以 smp_wmb 和 std::memory_order_release
为例,前者是双向的,后者是单向的。
1 | a = 1; |
这里 smp_wmb
是双向的死墙,上面的掉不下来,下面的爬不上去。
1 | a = 1; |
而 std::memory_order_release
是单向的门,a = 1 和 b.store
之间有一道单向门,b.store 和 c = 1
之间没有任何门。a = 1 不准掉到 b.store
的后面去;但是 c = 1 可以偷偷跑到 b.store
的前面去。
为什么 C++ 要搞出这种单向的门呢?
- 为了性能:
smp_wmb()这种双向墙太笨重了,它不仅阻断了错误,也阻断了编译器和 CPU 硬件原本可以做的安全优化。它描述物理上怎么做。 - 为了语义:
std::memory_order_release这种单向门的语义更清晰了,它明确告诉我们:「我只关心之前的操作对之后的操作可见;我不关心之后的操作对之前的操作可见。」 这就像一个蟑螂屋,蟑螂只能从前门进,从后门出,不能反过来。(常常用在保护临界区)它描述逻辑要什么。
抽象层级的不同
前面我们讲到 smp_* 更关心 「物理怎么做」,而
std::memory_order_* 更关心 「逻辑上要什么」。
Linux Kernel 中的 smp_*
基于物理硬件队列,内核的代码之间面向机器。smp_wmb()
可以看作是针对硬件缺陷的补丁。
C++ 中的 Memory
Order:基于“先行发生(Happens-Before)”的图论模型。为了适配地球上所有的
CPU 架构,C++ 标准抹除了 Store Buffer 这些具体概念。以前面 Store Buffer
/ Invalidate Queue 的例子,C++ 保证的是:如果线程 A 执行了
b.store(release),且线程 B 执行了
b.load(acquire) 并读到了 A 写入的值,那么 A 的 store 就
Synchronizes-With(同步于) B 的 load。进而推导出
a = 1 Happens-Before(先行发生于)
assert(a == 1)。只要这个逻辑推导成立,C++
编译器就会去负责干脏活累活。
生成的机器指令可能完全不同
还是以这两段代码为例子。
Memory Barrier:
1 | // Runs on CPU 0 |
C++ Memory Order:
1 | int a = 0; // a can be non-atomic. |
这两段代码在不同的 CPU 架构上,编译器生成的汇编指令是不同的。
在 x86-64 架构下(强内存模型 TSO): x86 硬件本身就保证了 Store-Store、Load-Load 不会乱序。
smp_wmb()和smp_rmb()在 x86-64 退化成纯粹的编译器屏障asm volatile("":::"memory"),不生成任何机器指令,只用来告诉编译器不要乱序(0 运行时开销)。std::memory_order_release和std::memory_order_acquire也在 x86-64 退化成纯粹的编译器屏障asm volatile("":::"memory"),也只生成普通的MOV指令,两者性能一致。
而在 ARM 架构下(弱内存模型),乱序是常态。
smp_wmb()生成DMB ISHST,smp_rmb()生成DMB ISHLD(这是一个非常重的全量屏障指令)。- 而 ARMv8 专门为 C++ 设计了单向屏障
STLRStore-Release 和LDARLoad-Acquire。
x86 TSO 内存模型
TSO 和 Memory Barrier / Memory Order
x86 的 TSO(Total Store Order,完全写序)模型天生有极强的顺序保证,它只允许 Store-Load 乱序。
- Load-Load:不乱序
- Store-Store:不乱序
- Load-Store:不乱序
- Store-Load:允许乱序
其原因是:现代 CPU 为了掩盖写主存的巨大延迟,引入了 Store Buffer。当核心执行写操作时,数据会被扔进私有的 Store Buffer,然后立刻去执行后面的读操作。如果前面的写还没刷入 L1 Cache(没收到 MESI 协议的 Invalidate Ack),后面的读就已经完成了,在宏观上就表现为「先读后写」。
既然引进了 Store Buffer,为什么不导致 Store-Store 乱序呢?
在 x86 这种强内存模型(TSO)下,不会发生 Store-Store 乱序,根本原因是 x86 的 Store Buffer 是严格的 FIFO(先进先出)。
既然 L-L,S-S,L-S 都不乱序了,为什么这些场景下还需要内存屏障和内存序呢?
编译器依然会生成乱序代码。
- 在 x86 上,
smp_wmb/smp_rmb更多是为了管住编译器;而smp_mb则是为了处理 x86 唯一允许的 Store-Load 乱序。这里smp_mb会使用MFENCE或者LOCK前缀指令来强制排空 Store Buffer。 - Memory Order 也是同样的道理,
std::memory_order_release/std::memory_order_acquire是为了管住编译器;而std::memory_order_seq_cst则是为了处理 Store-Load 乱序。这里std::memory_order_seq_cst会使用MFENCE或者LOCK前缀指令来强制排空 Store Buffer。
x86 有 Invalidate Queue 吗?
在架构语义层面上,x86 确实没有(或者说不需要向软件暴露)Invalidate Queue。
x86 的 TSO 模型必须保证:如果核心 A 看到核心 B 已经写了值,那么核心 A 之后的所有读操作都必须能看到这个新值。为了维持这个承诺:
- 强制同步处理: x86 的核心收到 Invalidate 请求时候,会立刻处理(或者逻辑上表现为立刻处理),确保后续不回读到旧的缓存值。
- 硬件保障: x86 的硬件逻辑会监控失效消息。如果有一条 Load 指令正在流水线中,而此时对应的 Cache Line 被失效了,CPU 往往会 丢弃并重新执行 该 Load 指令,以确保数据的强一致性。
虽然从软件开发者(汇编/C++)视角看,x86 没有 Invalidate Queue,但在现代 Intel / AMD 的微架构内部,其实存在类似的接收缓冲区。它的特点是:软件不可见,硬件自动同步。
TSO 中的 Read-Modify-Write 原子操作
无论是 FAA 还是 CAS,都属于 RMW
操作,它并不是一步完成的,是实打实的三部,但是又要保证原子性,于是就要上某种锁。所以他们看上去逻辑安全,但是
LOCK 前缀依然会独占 Cache Line,导致延迟上升。
早期的 CPU 非常变态,LOCK
前缀会直接锁住整个物理前段总线(Front-Side Bus),即一个核
LOCK 的时候其他的核连内存都不能碰;现代的 x86 CPU
引入了聪明的优化:缓存锁(Cache Locking),它利用底层的 MESI
协议。当核心执行 LOCK XADD 时,它会向所有核心发广播(或者
P2P),强制要求自己把这个变量所在的 Cache Line(缓存行,通常是 64 字节)
升级为 Modified(独占修改)状态。在 RMW
周期内,它被当前的核心死死拿在手里。
试想如果 8 个核心都在运行这段代码:
1 | while(true) { |
CPU 的内部网络会被海量的 Invalidate 信息和 Cache 数据的传输塞满(ownership 在不同的核之间流转);8 个核心同时争抢同一个缓存行的时候,硬件底层的仲裁器(Arbiter)要花额外的时间来决定哪个核心先得到这个缓存行的所有权;第 8 个核心必须要等前面 7 个核心依次完成 「抢夺 - 计算 - 交出」 的全过程,在这个漫长的过程里,多数核心的流水线几乎处于全盘停顿(Stall)的状态。
为了解决这个问题,可以考虑:
- 化共享为私有: 不要让多个核心同时写一个全局变量;
- 缓存行对齐和填充: 确保每个核心访问的变量位于不同的缓存行,避免伪共享;
- 退避算法(Backoff): 争抢太激烈的时候,可以插入
_mm_pause()退避一下,给总线降低拥堵。
退避算法(Backoff) 也可以防止 Pipeline Flush:CPU 在死循环获取 spinlock 的时候会做 Speculative Execution,当锁的状态发生变化时,它必须把流水线里所有投机计算的结果全部作废(Flush),这个清空动作极其极其极其昂贵(巨大的延迟惩罚)。