6.1810 Lab - mmap
实验指导:Lab - mmap
这是 xv6 的最后一个实验,要实现 mmap 和 munmap 这两个 syscall。mmap 在现代操作系统中功能非常丰富,这个实验只要求实现 memory-mapped files,它可以把一个文件(或者它的一部分)以页为单位映射到内存中,从而以读写内存的方式读写文件。
1 | void *mmap(void *addr, size_t len, int prot, int flags, |
这是 mmap 和 munmap 的接口,详细的功能可以在手册上查到。为了简化实验,实验指导上提到:
- mmap 中的 addr 在测试用例中永远为 0,这也就意味着我们不需要实现 map 到用户指定的 va,最终 map 的 va 由内核任意指定。
- prot 规定这块内存区域是否可读 / 可写,flags 规定这快内存区域是否最终要把改动写回文件。
- offset 参数在测试用例中也永远为 0,表示每个 map 一定从文件头部开始。
- munmap 的时候只会对原来 map 出来的区域掐头或者去尾,不会在中间挖个洞。(这个很大程度上减少了工作量)
实验指导要求 map 出的内存区域是懒加载的,也就是说:
- 页面不在 sys_mmap 里分配,而是在第一次发生 page fault 的时候分配。也就是我们要在 usertrap 这个函数里,拦截对应的 page fault,这一点很像 COW Fork 实验中的实现。
- 如果用户 map 了 10 个页面,但是只访问了其中一个页面,那只有这个页面真正被分配出来。
还有一些零碎的信息是指南上没有提到但是可以在 Linux 手册上看到的,了解这些有助于我们理解最后的 corner cases:
- munmap 的地址必须是页对齐的。
- mmap 不能改变文件的大小,也就是回写的时候最后一块如果不足一个 page,不能把一个 page 都写入文件。
- mmap / munmap 的 len 如果不是页对齐的,会被自动 round-up。
思路
首先我们先按照指南的要求更改 make file 和添加系统调用,让代码可以编译。
VMA Slots
我们需要一个结构来 per-process 地保存 mmap 的信息(哪些 va 被 map 了,map 到了哪个文件,等等),然后把它加在 PCB 里(我把它叫做 vma slots)。
- 每个 process 最多有 16 个这样的 slots(指南上写的),可以直接用数组来表示,每个 vma slot 都有一个 valid 标记,如果它是 1 的话表示这个 slot 被使用了,否则就是空的。
- va 字段是最终 mmap 分配出来的虚拟地址,len / prot / flags / f 是系统调用的参数。
- 虽然指南上说 offset 一直为 0,但是我这里还是维护了一个 offset,因为 munmap 可能会掐头,那么这个时候的 va 就会发生改变。在后面的流程中,保留一个 original va 是很有必要的,因为它可以计算出回写文件的 offset(下文回提到),所以这边需要一个额外的变量来维护已经掐掉并往后推移的头(munmap 之后的起始 va),所以我引入了 offset。(下文中会有它的具体用法)
1 |
|
虚拟内存分配策略
mmap 需要为用户分配一块长度为 len 的虚拟地址空间,如果这个空间在堆上随意分配的话,可能会和 sbrk 冲突(sbrk 在堆上从低地址向高地址生长,且虚拟内存连续),那最好的策略就是找一个离 sbrk 活跃区域比较远的地方。
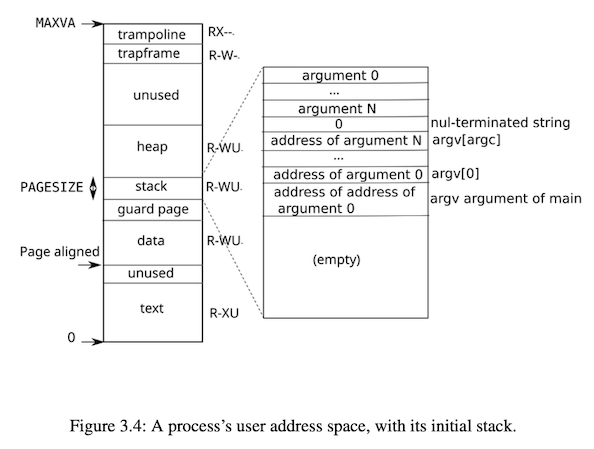
这里可以选择 unused 区域的最顶部,也就是 trampoline 和 trapframe 的下方,从高地址往低地址生长,这种情况下最不容易和 sbrk 冲突。我在这个实验里是直接从这个位置向下分配的,mmap 要多少就给多少,有一个 top 指针(初始指向 trapframe 下方)指向可以分配的位置,然后随着分配出新的空间 top 的值越来越小。这个方法有个问题就是可能会导致内存碎片,不过通过这个 lab 是可以的。
于是我们得到这样的 PCB:
1 | // Per-process state |
在 allocproc 创建新进程的时候设置这个 top 指针:
1 | static struct proc* |
sys_mmap
这样我们就可以写出 sys_mmap 了。这里我们要先 check 一下用户希望 map 的这个操作是否合法:
- 如果文件不可读,但是用户 prot 中含有 PROT_READ,它就是不合法的。
- 如果文件不可写,但是用户 prot 中含有 PROT_WRITE,这里还需要分成两种情况:如果它是 MAP_PRIVATE,即不同步回文件,只在内存里写,这是合法的;否则就是非法的。
这里需要对不对齐的 len 做 round-up。
这里还有个坑点事 argfd 是不做 ref-count 的,我们把 fd 转程 file 之后,需要做一次 filedup 来维护这个文件对象的 ref-count,确保它的生命周期不会在我们使用它的时候结束。
1 | uint64 sys_mmap(void) |
懒加载 / Page Fault 处理
sys_mmap 并没有分配页面,只是记录下来这里有个这样的 map。真正的分配在 page fault(下面简称 PF)的时候。我们这里要像 COW Fork 处理 PF 时一样,拦截这个 PF,然后分配页面。
和 COW Fork 不同的是:COW Fork 只拦截 scause = 15 的 PF,它代表用户尝试写一个非法的 page;这里 mmap 还可能读到非法的 page,所以我们要拦截 scause = 13 和 scause = 15 两种情况。我们可以从寄存器中拿到发生 PF 的 va,第一步是取 PCB 的 vma slots 里面查查这个 va 是不是 mmap 出来的,如果是我们就分配一个 page。这里只分配一个 page,因为只访问了这个 page(懒加载)。code 大致长这样:
1 | // in usertrap() function: |
这里 mmap_find_vma 不仅要查看这个 va 在不在 slot 里,还需要检查一下权限,看看用户是不是想读不该读的或者想写不该写的。
1 | struct mmap_vma *mmap_find_vma(uint64 pf_va, uint64 pf_cause) |
mmap_handle 负责页面分配、页面映射以及把文件中的数据加载到内存里。
- 这里要注意分配完之后要把内存页面 memeset 清零,有个 case map 了 1.5 个页面,会检查剩下的 0.5 个页面是不是全 0。由于 xv6 在分配内存的时候会 memset 写一些垃圾数据,如果不手动 memset 清零的话测试程序就会读到这些垃圾数据。
- 还有个坑点是 readi 读文件的时候要 lock 住 inode。后面我们用 writei 写文件的时候不光要 lock,还需要用事务,因为写文件要落盘,要经过日志系统保证原子性和故障恢复。这个点很容易被忽略。
1 | int mmap_handle(uint64 pf_va, struct mmap_vma *vma) |
sys_munmap
下面我们来实现 sys_munmap,munmap 一段内存可能会掐头或者去尾,也就是我们要维护对应的 vma slot 里的信息。这里我把维护 vma slot 信息的功能单独抽出来写了一个函数 mmap_release,表示从给定的 vma 中 unmap [va, va + len),方便 exit 函数复用。
1 | uint64 sys_munmap(void) |
由于页面事懒加载的,mmap_release 并不能直接从 vma 得知哪些 page 是真正被分配出来的,我们可以遍历 [va, va + len) 范围内所有的 page,检查是否有 PTE,如果有我们再去做真正的 uvmunmap。
当然在 uvmunmap 之前还要把 MAP_SHARE 的内存写入磁盘。要注意:
- writei 需要上锁,并且要使用事务。
- mmap / munmap 不能改变文件大小,所以如果原来最后一个块是 round-up 上来的,不能整块写入。
在这个过程当中,我们还需要维护一个 vma slot 的开头和结尾,而我们又要保留 original va(通过 va offset 来推算文件的 offset)。这个时候 vma->offset 就有作用了,如果被「掐头」了,vma->va 后移 len 个字节,那么就在 vma->offset 上增加 len,这样这个内存的头部位置相对于 original va 的 offset 就是 vma->va - vma->offset。
当然我们还有维护 vma->len,当它变成 0 的时候我们就可以释放出这个 slot 了。
1 | // To unmap [va, va + len) from the vma_idx-th vma. |
这个地方坑点很多。除了上面的要点之外,还要注意 PTE 不存在和 PTE 非法的时候都不做处理(后者容易漏掉)。这么理解:
- pte == 0 代表 PTE 不存在,也就是 L0 级的 PT 还没被创建出来。
- pte != 0 但是 pte 不含 PTE_V 的时候意味着 L0 PT 被创建出来了,但是这个 PTE 本身是空的。
这个部分的问题的本质其实是 unmap 掉页表树上一个指定区间的叶子结点,也可以从页表树 dfs 下去,这样时间复杂度就变成了真正创建的 L0 页表里 PTE 的总数,在 mmap 一大段内存并且真实访问到的页面很稀疏的情况下这样会比较高效。不过这个方法复杂一些,并且 mmaptest 的测试用例也不是这种 case,那我们就不整活儿了。
exit
没有被 munmap 的页面在 process 结束的时候也需要被释放掉。mmap 的页面并不能被已有的流程回收,我们需要在 exit 函数里单独回收这些页面,调用我们前面实现的 mmap_release。
1 | void |
fork
最后,我们要修改 fork,保证 vma slots 和 mmap 的信息也被 copy 到了子进程里面。这里要注意 vma slots 里的文件需要在这里再次维护 ref-count,因为新增了饮用者。
1 | int |
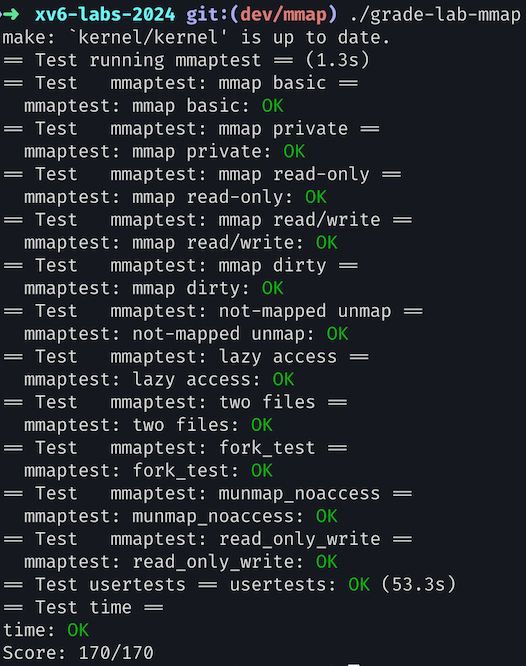
实验结果