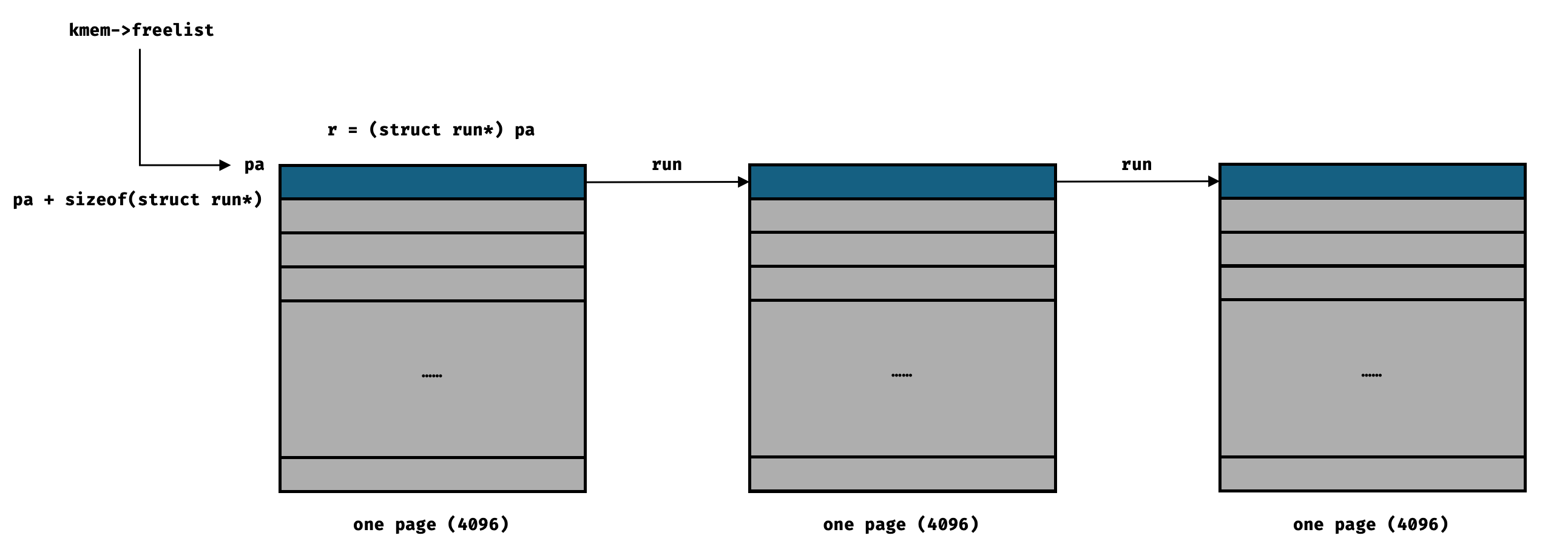
void kinit() { for (int i = 0; i < NCPU; ++i) { initlock(&kmem[i].lock, "kmem"); }
freerange(end, (void*)PHYSTOP); }
void freerange(void *pa_start, void *pa_end) { char *p; p = (char*)PGROUNDUP((uint64)pa_start); for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) kfree(p); }
// Free the page of physical memory pointed at by pa, // which normally should have been returned by a // call to kalloc(). (The exception is when // initializing the allocator; see kinit above.) void kfree(void *pa) { structrun *r;
// Disable interrupts for getting CPU ID. push_off();
// Allocate one 4096-byte page of physical memory. // Returns a pointer that the kernel can use. // Returns 0 if the memory cannot be allocated. void * kalloc(void) { structrun *r;
// Disable interrupts for getting CPU ID push_off();
int cpu = cpuid();
acquire(&kmem[cpu].lock); r = kmem[cpu].freelist; if (r) kmem[cpu].freelist = r->next; release(&kmem[cpu].lock);
// No pages are available from current CPU's freelist, // now let's attempt to steal one from another CPU. if (!r) { for (int i = 0; i < NCPU; ++i) { if (i == cpu) { continue; } acquire(&kmem[i].lock); r = kmem[i].freelist; if (r) { kmem[i].freelist = r->next; release(&kmem[i].lock); break; } else { release(&kmem[i].lock); } } }
// Re-enable interrupts. pop_off();
if(r) memset((char*)r, 5, PGSIZE); // fill with junk
这里需要从头实现一个哈希表来代替原来的 bcache
结构。我实现了一个开散列的哈希表,哈希函数是对素数取模。由于开散列的哈希表要实现一个链表,这里需要预分配一些
buffers 给链表节点使用:我们可以直接用原来的 struct buf
结构作为链表节点(因为它天然有 next / prev
指针),预分配一个全局的数数组给链表的节点。任务里说「You must not
increase the number of buffers; there must be exactly NBUF (30) of
them.」,那么这里数组的长度我们就还分配 NBUF。
releasesleep(&b->lock); uint hash = hash_blockno(b->blockno); acquire(&buckets[hash].lock); b->refcnt--; if (b->refcnt == 0) { // No one is waiting for it. // Move this buffer node away from the bucket, // then free the buffer node // (returning it back to the freeblocks list). b->next->prev = b->prev; b->prev->next = b->next; buf_free(b); } release(&buckets[hash].lock); }