实验指导:Lab -
Networking
Part One: NIC
这个任务需要实现 E1000 网卡驱动。具体地,kernel/e1000.c 中的
e1000_transmit 和 e1000_recv 两个函数。
NIC 驱动执行的两个上下文
Many device drivers execute code in two contexts: a top half that
runs in a process's kernel thread, and a bottom half that executes at
interrupt time.
如 xv6 book 所描述的那样,这里我们实现的 NIC
的驱动也运行在两个不同的上下文环境:进程的内核态、中断时。
e1000_recv 会在中断上下文中被调用:当有新的以 ethernet
frame 来临的时候,E1000 会通过 DMA
的方式把接受到的包写入内存中的缓冲区,然后通过中断的方式告诉 xv6
有新的数据包来了,xv6 陷入内核,通过 usertrap - devintr - e1000_intr -
e1000_recv 调用,e1000_recv 负责处理收到的 ethernet frame,并把 ethernet
frame 拆解成 IP / ARP / UDP 等数据做进一步处理。
e1000_transmit 会在两个上下文中被调用到:
一是用户程序发包的时候,使用 send 系统调用,sys_send 中把数据按照
UDP - IP - Ethernet 的方式一层一层打包,最后把打包好的数据通过 NIC
提供的 e1000_transmit
发送出去。这里的运行上下文是用户程序的内核态。
第二个场景是 e1000_recv 会使用 net_rx 来接收 ethernet frame,net_rx
会根据 ethernet frame header 中的 type 信息来分流给 ip_rx 和
arp_rx。如果是一个 ARP 请求包的话,arp_rx 需要回复一个 ARP
响应,这个时候会调用 e1000_transmit
发包。这里的运行上下文是中断时。
e1000_transmit
e1000_transmit(char *buf, int len),负责让 E1000 发送出
buf 指向的内容,长度为 len bytes。
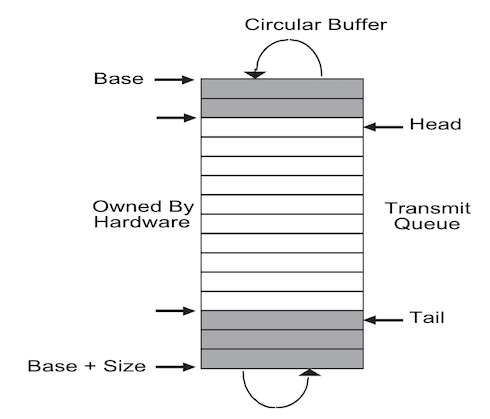
对于发包的场景,E1000 管理一个环形缓冲区。这个环形缓冲区用来存放
Transmit Descriptor 这个数据结构,在 xv6 的代码中它叫
tx_desc,这个结构在手册的 3.4 节中有说明。xv6 会在加载
E1000 驱动的时候运行初始化代码
e1000_init,这里会把这个环形缓冲区的地址写入到 E1000 的
TDBAL 寄存器内,写网卡寄存器是通过 MMIO
来实现的。这里还会初始化其他信息,比如这个缓冲区的长度,这个环形缓冲区(即循环队列)的队头和队尾等等。
我们需要把待发的包的元数据,即一个 tx_desc
实例写入这个环形缓冲区中,它会告诉网卡:待发数据的起始地值、长度、发送行为等等信息。这些信息都用来告诉网卡如何发送这些数据。接着我们要修改
TDT
寄存器(环形缓冲区的队尾),这一步既是操作队列,也是一种对网卡的通知,3.4.1
中写道:
When the on-chip buffer is empty, a fetch happens as soon as any
descriptors are made available (software writes to the tail
pointer).
这个机制有点类似于条件变量的唤醒。看上去像是修改 TDT
后有一次边沿触发。
下面我们就可以实现这个函数了。需要注意的是:
要给 tx_ring
上锁。因为可能同时有两个不同的进程发包,并且这两个进程并行地运行在两个
CPU 上。
写入 descriptor 结构前要检查当前 tx_ring
上写入位置的状态。如果没有置位
E1000_TXD_STAT_DD(Descriptor Done
Bit),则说明网卡还没有处理完当前的位置,不能写入。
要释放已经发完的包的内存。
写入 descriptor 结构时,要清空状态,并且设置
E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS 行为。EOP
代表当前描述符是构成一个完整数据包的最后一个描述符,RS
代表处理完该描述符后写回状态信息到主机内存的描述符中(例如 DD
位,这样下次发包就可以判断当前位置是否可写)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int e1000_transmit (char *buf, int len) acquire(&e1000_lock); uint32 idx = regs[E1000_TDT]; if (!(tx_ring[idx].status & E1000_TXD_STAT_DD)) { release(&e1000_lock); return -1 ; } if (tx_ring[idx].addr) { kfree((void *)tx_ring[idx].addr); } tx_ring[idx].addr = (uint64)buf; tx_ring[idx].length = len; tx_ring[idx].cmd = E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS; tx_ring[idx].status = 0 ; regs[E1000_TDT] = (idx + 1 ) % TX_RING_SIZE; release(&e1000_lock); return 0 ; }
e1000_recv
E1000 收包时,会先把数据 DMA 到内存,然后修改 rx_ring
的部分内容(状态、地址等),然后通过中断告诉 xv6 有新的数据来了。
接着 xv6 就会处理这个中断,经过层层调用(usertrap - devintr -
e1000_intr - e1000_recv)来到 e1000_recv 这个函数。
e1000_recv 需要处理(接收)RDT(接收描述符队列 rx_ring
队尾)的数据,然后调用 net_rx 处理数据。net_rx 接收 ethernet
frame,分流给 arp_rx 和 ip_rx,ip_rx 会继续分流给传输层协议。
与 e1000_transmit 相似地,我们可以实现 e1000_recv。需要注意:
同样需要检测 DD 位。
net_rx 会把 rx_ring descriptor 中的 addr 指向的内存页面给 kfree
掉,所以我们需要在 net_rx 结束后分配一个新的 page 并重置描述符。
实验描述中说「The e1000 can deliver more than one packet per
interrupt; your e1000_recv should handle that
situation.」所以这里要循环收包,把能收的都收住。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 static void e1000_recv (void ) while (1 ) { uint32 idx = (regs[E1000_RDT] + 1 ) % RX_RING_SIZE; if (!(rx_ring[idx].status & E1000_RXD_STAT_DD)) { return ; } net_rx((char *)rx_ring[idx].addr, rx_ring[idx].length); if (!(rx_ring[idx].addr = (uint64)kalloc())) { panic("e1000_recv kalloc failed" ); } rx_ring[idx].status = 0 ; regs[E1000_RDT] = idx; } }
Part Two: UDP Receive
这部分的任务是实现 sys_recv 和 sys_bind 两个系统调用,其中 sys_recv
的目标是实现 UDP 的接收。
生产者-消费者
这里对于每一个被绑定的 port,都存在一对「生产者-消费者」。
这里的生产者是 net_rx 函数:每当网卡检测到有新的数据可以被 receive
的时候,会触发一个中断,中断处理函数会调用 net_rx,net_rx 会把
ethernet_frame 按照协议分流。那么对于 UDP 来说,net_rx 会分流给
ip_rx,接着 ip_rx 需要分流给一个 UDP
协议的接收函数,这个函数是我们要实现的,这里我们把它叫做 udp_rx。udp_rx
应该把 UDP 包的数据放入一个队列中,等待用户程序消费。
这里的消费者是 sys_recv
系统调用:用户程序主动调用这个系统调用来消费队列中的 UDP
包,如果队列为空则等待生产者向队列中推送数据,即等待新数据来的中断。这里的等待需要用到
kernel/proc.c 中的 sleep - wakeup 机制,有点像条件变量。
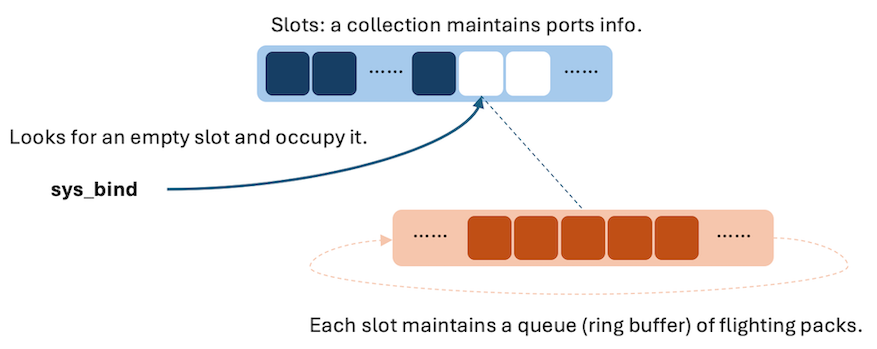
端口集合
对于每一个被绑定的端口,我们都要维护一个队列,这里我们可以用 ring
buffer
来实现。并且我们需要维护一个已经绑定的端口的集合,这样生产者和消费者才能定位到一个具体的队列。
这样每次调用 sys_bind
的时候就是开始启用这个集合中的一个新的槽位。sys_unbind
就是释放一个制定的槽位。
这里我就简单地用数组来实现这个集合,因为:如果只是为了通过 xv6
的测试,这里我们不需要预留很多槽位。
对于每个槽位,我们需要维护端口号以及刚刚我们提到的 ring buffer。ring
buffer 需要维护目前队列中元素的个数(flighting
packs),头、尾指针,以及每个 pack 的数据。对于每个 pack,我们要维护源
IP,源端口号,UDP 数据,以及 receive
结束后我们需要释放的缓冲区的首地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #define MAX_PORT_SLOTS 20 static struct { uint16 port; uint8 in_flight; uint8 r_idx; uint8 w_idx; struct spinlock port_lock ; struct { int src_ip; short sport; char *buf; char *buf_owner; int len; } ring[16 ]; } ports_info[MAX_PORT_SLOTS];
我们需要初始化这些槽位。
1 2 3 4 5 6 7 8 9 void netinit (void ) initlock(&netlock, "netlock" ); memset (ports_info, 0 , sizeof ports_info); for (int i = 0 ; i < NPROC; ++i) { initlock(&ports_info[i].port_lock, "net_portlock" ); } }
于是我们可以实现 sys_bind:
sys_bind 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 uint64 sys_bind (void ) int port; argint(0 , &port); for (int i = 0 ; i < MAX_PORT_SLOTS; ++i) { acquire(&ports_info[i].port_lock); if (ports_info[i].port != 0 ) { release(&ports_info[i].port_lock); continue ; } ports_info[i].in_flight = 0 ; ports_info[i].r_idx = 0 ; ports_info[i].w_idx = 0 ; ports_info[i].port = port; memset (ports_info[i].ring, 0 , sizeof (ports_info[i].ring)); release(&ports_info[i].port_lock); break ; } return 0 ; }
ip_rx / udp_rx
下面我们就可以按照这个思路来修改生产者端的 ip_rx 函数,并且加入
udp_rx 函数。
ip_rx 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void ip_rx (char *buf, int len) static int seen_ip = 0 ; if (seen_ip == 0 ) printf ("ip_rx: received an IP packet\n" ); seen_ip = 1 ; struct eth *ineth = struct ip *inip =1 ); switch (inip->ip_p) { case IPPROTO_UDP: udp_rx(buf, len); break ; default : kfree(buf); break ; } }
udp_rx 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void udp_rx (char *buf, int len) struct eth *ineth = struct ip *inip =1 ); struct udp *inudp =1 ); uint32 src_ip = ntohl(inip->ip_src); uint16 dport = ntohs(inudp->dport); uint16 sport = ntohs(inudp->sport); uint16 blen = ntohs(inudp->ulen) - sizeof (struct udp); int i; int port_idx = -1 ; for (i = 0 ; i < MAX_PORT_SLOTS; ++i) { acquire(&ports_info[i].port_lock); if (ports_info[i].port != dport) { release(&ports_info[i].port_lock); continue ; } else { port_idx = i; release(&ports_info[i].port_lock); break ; } } if (port_idx == -1 ) { kfree(buf); return ; } acquire(&ports_info[port_idx].port_lock); if (ports_info[port_idx].in_flight >= 16 ) { kfree(buf); release(&ports_info[port_idx].port_lock); return ; } uint8 w_idx = ports_info[port_idx].w_idx; ports_info[port_idx].ring[w_idx].src_ip = src_ip; ports_info[port_idx].ring[w_idx].sport = sport; ports_info[port_idx].ring[w_idx].buf = (char *)(inudp + 1 ); ports_info[port_idx].ring[w_idx].len = blen; ports_info[port_idx].ring[w_idx].buf_owner = buf; ports_info[port_idx].in_flight++; ports_info[port_idx].w_idx = (w_idx + 1 ) % 16 ; release(&ports_info[port_idx].port_lock); wakeup(&ports_info[port_idx]); return ; }
sys_recv
接着我们可以实现消费者端的 sys_recv 了。sys_recv 要做的事情就是把
ring buffer 中的数据复制到指定的用户地址空间中(使用
copyout),然后把内核中为接收这个 pack 分配的页面给释放掉。
sys_recv 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 uint64 sys_recv (void ) int dport; uint64 p_src_ip; uint64 p_src_port; uint64 p_dest_buf; int maxlen; int i; int port_idx = -1 ; struct proc *p = pagetable_t pt = p->pagetable; argint(0 , &dport); argaddr(1 , &p_src_ip); argaddr(2 , &p_src_port); argaddr(3 , &p_dest_buf); argint(4 , &maxlen); for (i = 0 ; i < MAX_PORT_SLOTS; ++i) { acquire(&ports_info[i].port_lock); if (ports_info[i].port != dport) { release(&ports_info[i].port_lock); continue ; } else { port_idx = i; release(&ports_info[i].port_lock); break ; } } if (port_idx == -1 ) { return -1 ; } acquire(&ports_info[port_idx].port_lock); while (ports_info[port_idx].in_flight == 0 ) { sleep(&ports_info[port_idx], &ports_info[port_idx].port_lock); } int r_idx = ports_info[port_idx].r_idx; copyout(pt, p_src_ip, (char *) &ports_info[port_idx].ring[r_idx].src_ip, sizeof (uint32)); copyout(pt, p_src_port, (char *) &ports_info[port_idx].ring[r_idx].sport, sizeof (uint16)); int b_copied = maxlen; if (ports_info[port_idx].ring[r_idx].len < b_copied) { b_copied = ports_info[port_idx].ring[r_idx].len; } copyout(pt, p_dest_buf, ports_info[port_idx].ring[r_idx].buf, b_copied); kfree(ports_info[port_idx].ring[r_idx].buf_owner); ports_info[port_idx].r_idx = (r_idx + 1 ) % 16 ; ports_info[port_idx].in_flight--; release(&ports_info[port_idx].port_lock); return b_copied; }
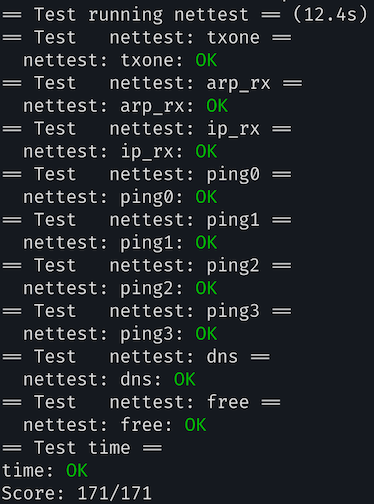
实验结果