实验指导:Lab -
Traps
COW Fork
这个实验要求为 xv6 实现 COW fork(Copy-on-Write:写时拷贝)。
COW 的意义
现有的 xv6 中的 fork
会在创建子进程的时候把父进程的内存页面都复制过来。这个复制在很多情况下是没有必要的,比如:
我们用 shell 启动程序的时候,fork 之后就会是一个 exec,exec 会抛弃被
fork 过来的内存页面,此时 fork 的 copy 就显得不是很有必要。
父进程和子进程同时访问一个 read-only 的页面。
那么,只有父进程和子进程需要写这个页面的时候,我们才真正需要用到拷贝,为页面创造副本。其他情况下,直接把子进程的虚拟页面
map 到父进程对应的页面即可,不需要 fork 时拷贝。
思路
实现 COW 需要:
uvmcopy 只建立映射,不直接
kalloc:fork 会使用 uvmcopy
把父进程的用户地址空间复制一份给子进程;但是 COW 要求在
fork
的时候不直接分配新的页面,而是让新的进程的地址空间先映射到老的进程的地址空间上,之后出现写操作再进行真正的分配和拷贝。引用计数:由于引入了页面的映射,在进程结束需要回收进程页面的时候,情况就会变得复杂一些,因为子进程仍然需要父进程的页面。这个时候需要对物理页进行引用计数,只有在引用为
0 的时候才释放这个页面。
处理 page fault:COW 利用了 page fault
机制,当父子进程当中的任意一个尝试写 COW 页面的时候,会触发 page
fault。这时操作系统内核需要把 COW
页面变成可写的页面,然后写操作将再次被执行。
COW 引发的 page fault 发生的本质是用户程序尝试写了一个不可写的
page,这个时候会陷入内核执行
usertrap,usertrap 可以根据
scause == 15 来识别这个 page fault,此时
$stval 寄存器里面保存着访问失败的 VA,我们可以根据这个 VA
找到对应的 PTE,修改 PTE 使得这个 VA 可写来处理 page fault。
引用计数
这里我们需要:
kalloc / kfree 时维护页面的引用数量提供修改引用计数的函数(引用加一,引用减一)给这些场景:
uvmcopy map处理 page fault 的时候分裂页面
kernel/defs.h 1 2 3 void k_page_ref_inc (uint64 pa) void k_page_ref_def (uint64 pa) int k_page_ref (uint64 pa)
下面考虑引用计数的数据结构。
这里引用计数是为了统计每个物理页面被映射的次数,从而判断是否应该回收这个页面。所以这里可以把物理地址作为
key;物理内存的大小是 PHYSTOP - KERNBASE 即
128 * 1024 * 1024,于是需要维护的页面数量就是 \(\frac{128 \times 1024 \times 1024}{4096} =
32768\) 个,可以用一个长度为 32768 的数组来记录。
由于每一个物理页面的引用计数可能被多个进程并发地访问,这里需要上锁。
kernel/kalloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #define PAGE_NUM ((PHYSTOP - KERNBASE) / PGSIZE) struct { struct spinlock lock [PAGE_NUM ]; int ref_cnt[PAGE_NUM]; } page_ref_cnt; void kinit () int i; initlock(&kmem.lock, "kmem" ); freerange(end, (void *)PHYSTOP); for (i = 0 ; i < PAGE_NUM; ++i) { initlock(&page_ref_cnt.lock[i], "page_ref_cnt" ); page_ref_cnt.ref_cnt[i] = 0 ; } }
接着我们就可以实现这三个函数了:
kernel/kalloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void k_page_ref_inc (uint64 pa) uint64 key = ((uint64)pa - KERNBASE) >> 12 ; acquire(&page_ref_cnt.lock[key]); page_ref_cnt.ref_cnt[key] += 1 ; release(&page_ref_cnt.lock[key]); } void k_page_ref_dec (uint64 pa) uint64 key = ((uint64)pa - KERNBASE) >> 12 ; acquire(&page_ref_cnt.lock[key]); page_ref_cnt.ref_cnt[key] -= 1 ; release(&page_ref_cnt.lock[key]); } int k_page_ref (uint64 pa) uint64 key = ((uint64)pa - KERNBASE) >> 12 ; acquire(&page_ref_cnt.lock[key]); int ref_c = page_ref_cnt.ref_cnt[key]; release(&page_ref_cnt.lock[key]); return ref_c; }
uvmcopy
下面我们要修改 uvmcopy 函数:
在 uvmcopy
中,我们需要把原本的分配新页面的步骤去掉。
对于原来就是只读的页面,这种页面永远不会被写到,所以不需要打
PTE_COW 标记;对于原来可写的页面,在这里我们需要把
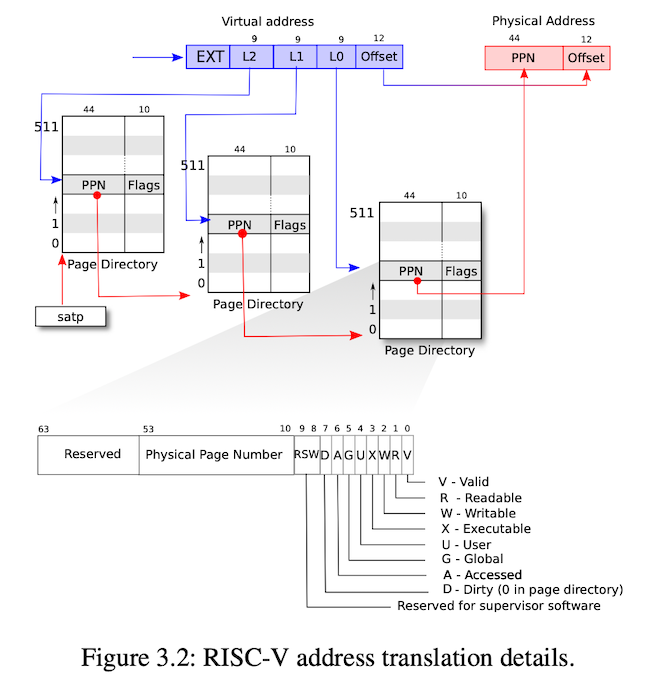
PTE_W 去掉,然后打上 PTE_COW 标记。riscv SV39
的 PTE 预留了两个 RSW 位,我们可以用其中一个来实现
PTE_COW(这里我选用了
1 << 8)。这一步意味着:在真正的写操作发生之前,父子进程读的是同一个物理页面,而写操作发生之后,会发生页面分裂(此时是真正的分配新页面),PTE_COW
被删除,PTE_W 被恢复。
接下来就是把原来的 map 到新分配页面的逻辑改成 map
到现有的页面。原来的代码中,如果页面 map 失败,会 kfree
来释放掉分配好的页面,并且进行回滚 unmap 掉以及 map
的页面。这里我们没有真正分配页面,所以不用调用
kfree,但是在回滚时除了 unmap,还需要把已经打上
PTE_COW 标签的 PTE 恢复成可写。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 int uvmcopy (pagetable_t old, pagetable_t new , uint64 sz) pte_t *pte; uint64 pa, i, j; uint flags; char *mem; for (i = 0 ; i < sz; i += PGSIZE){ if ((pte = walk(old, i, 0 )) == 0 ) panic("uvmcopy: pte should exist" ); if ((*pte & PTE_V) == 0 ) panic("uvmcopy: page not present" ); if (PTE_FLAGS(*pte) & PTE_W) { (*pte) |= PTE_COW; (*pte) &= (~PTE_W); } pa = PTE2PA(*pte); flags = PTE_FLAGS(*pte); mem = (char *)pa; if (mappages(new , i, PGSIZE, (uint64)mem, flags) != 0 ){ goto err; } k_page_ref_inc(pa); } return 0 ; err: for (j = 0 ; j < i; j += PGSIZE) { pte = walk(old, j, 0 ); if (PTE_FLAGS(*pte) & PTE_COW) { (*pte) &= (~PTE_COW); (*pte) |= (PTE_W); } } uvmunmap(new , 0 , i / PGSIZE, 1 ); return -1 ; }
触发 COW
下面处理写时拷贝。有两个地方需要 COW:
usertrap 发现 page fault 并且这个 page fault
是由用户程序写了不可写的内存导致的时候;copyout
函数需要把内核中的数据复制给用户,这个时候也有可能会触发 COW。
所以我们预期这两个地方会这样调用:
usertrap 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void usertrap (void ) if (r_scause() == 8 ) { } else if ((which_dev = devintr()) != 0 ) { } else if (r_scause() == 15 ) { int res = k_try_cow(p->pagetable, r_stval()); if (res == 0 ) { } else { printf ("usertrap(): COW failed, res = %d, pid=%d\n" , res, p->pid); setkilled(p); } } else { } }
copyout 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int copyout (pagetable_t pagetable, uint64 dstva, char *src, uint64 len) uint64 n, va0, pa0; pte_t *pte; while (len > 0 ){ va0 = PGROUNDDOWN(dstva); if (va0 >= MAXVA) return -1 ; pte = walk(pagetable, va0, 0 ); if (pte != 0 && (*pte & PTE_COW)) { if (k_try_cow(pagetable, va0) == 0 ) {} else return -1 ; } if (pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0 || (*pte & PTE_W) == 0 ) return -1 ; pa0 = PTE2PA(*pte); n = PGSIZE - (dstva - va0); if (n > len) n = len; memmove((void *)(pa0 + (dstva - va0)), src, n); len -= n; src += n; dstva = va0 + PGSIZE; } return 0 ; }
实现 COW
下面我们需要实现这个 k_try_cow。
这个函数做的事情其实就是前面提到的页面的分裂。大致地,它有四个步骤:分配新页面并更新引用计数,重置
PTE_W 和 PTE_COW,map
新页面,拷贝数据(从老页面到新页面)。
这里我们需要考虑一个页面被 fork 两次以上的情况(引用计数 >=
3),可以看出同时重置父子页面的 PTE_W /
PTE_COW 并不是一个正确的方案,因为一个页面可以从
PTE_COW 变成 PTE_W
的条件一定是它的引用计数只有 1
了(即它是新分配的页面)。也就是说,当引用计数为 3 的时候,触发了一次
COW:新页面的引用是 1,可写;老的物理页面的引用变成
2,PTE_COW 应该被保留。
我们这里只操作当前虚拟地址需要的页面。如果是分裂出一个新的页面,那我们只改这个页面的
flag。这样就会存在:有的页面引用数为 1 了,但是仍然还是有
PTE_COW,不可写。对于这样的页面,我们只需要在它触发 COW
的时候让它从 PTE_COW 变成 PTE_W 就行了。
这里考虑引用数 >= 3 很重要,因为我一开始只考虑引用 = 2 的情况,在
three 这个 test case
挂掉了,于是发现同时改父子进程的物理页是有问题的。
因此,这里对于引用计数为 1 的页面,我们需要重制
flags;否则,四个步骤都需要做。map 新页面的步骤其实不用调用
mappages 函数,因为我们已经有 pte 了,只需要改这个 pte
就可以完成 map,这样可以省去 mappages 中再去 walk 的时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 int k_try_cow (pagetable_t pt, uint64 va) pte_t *pte; uint64 pa; void *new_page; if (va >= MAXVA) { return -1 ; } if ((pte = walk(pt, va, 0 )) == 0 ) { return -1 ; } if (!(PTE_FLAGS(*pte) & PTE_COW)) { return -1 ; } pa = PTE2PA(*pte); if (k_page_ref(pa) == 1 ) { *pte = ((*pte) & (~PTE_COW)) | (PTE_W); return 0 ; } if ((new_page = kalloc()) == 0 ) { return -1 ; } k_page_ref_dec(pa); *pte = ((*pte) & (~PTE_COW)) | (PTE_W); *pte = PA2PTE(new_page) | PTE_FLAGS(*pte); memmove(new_page, (void *)pa, PGSIZE); return 0 ; }
至此,cowtest 就可以通过了。
测试结果
在做这个实验的过程中,除了引用数 >= 3
的情况需要考虑,还有一个比较坑的的就是 walk 返回 0 的情况,这个 0 不是
PTE,而是表示 NULL,这里不能对这个 PTE 解引用,否则会产生 kernel
trap。解决这个问题之后 usertests 也可以通过了。