实验指导:Lab - Page
Tables
Inspect a user-process page
table
运行 pgtbltest,print_pgtbl 会打印最前面的 10
个和最后面的 10
个页。这个任务是通过输出理解这些页面包含了什么、权限位是什么,以理解 xv6
user space 的内存组织结构。
pgtbltest's output 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 va 0x0 pte 0x21FC885B pa 0x87F22000 perm 0x5B va 0x1000 pte 0x21FC7C17 pa 0x87F1F000 perm 0x17 va 0x2000 pte 0x21FC7807 pa 0x87F1E000 perm 0x7 va 0x3000 pte 0x21FC74D7 pa 0x87F1D000 perm 0xD7 va 0x4000 pte 0x0 pa 0x0 perm 0x0 va 0x5000 pte 0x0 pa 0x0 perm 0x0 va 0x6000 pte 0x0 pa 0x0 perm 0x0 va 0x7000 pte 0x0 pa 0x0 perm 0x0 va 0x8000 pte 0x0 pa 0x0 perm 0x0 va 0x9000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFF6000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFF7000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFF8000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFF9000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFFA000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFFB000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFFC000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFFD000 pte 0x0 pa 0x0 perm 0x0 va 0xFFFFE000 pte 0x21FD08C7 pa 0x87F42000 perm 0xC7 va 0xFFFFF000 pte 0x2000184B pa 0x80006000 perm 0x4B
对内容稍加整理可以发现中间的大部分 pages 是未使用的(有效位 flag
PTE_V 是 0)。
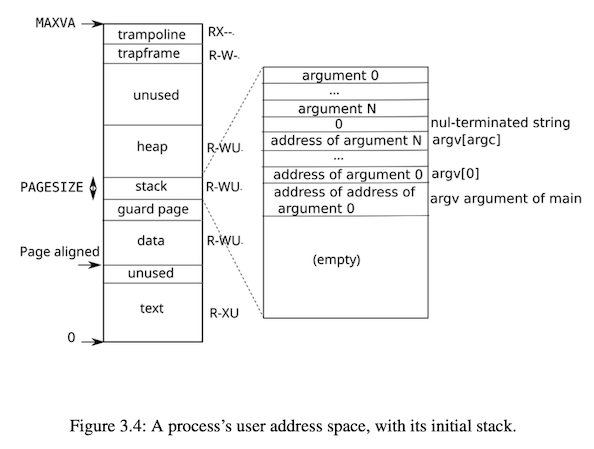
根据 kernel/memlayout.h 中的定义以及 xv6 book 中的图 3.4,user space
最高的两个页面分别是 trampoline 和 trapframe。也可以从 permission mask
看出:trampoline 页可读可执行,但是不可写,用户态不可访问;trapframe
可读写,不可执行,用户态不可访问;与图 3.4 一致。
用同样的方法可以判断出低地址的四个页面分别是 Text,Data,Guard 和
Stack。
answer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 va pte pa perm 0x0 0x21fc885b 0x87f22000 VR-XU -> Text (program to execute) 0x1000 0x21fc7c17 0x87f1f000 VRW-U -> Data 0x2000 0x21fc7807 0x87f1e000 VRW-- -> Guard 0x3000 0x21fc74d7 0x87f1d000 VRW-U -> Stack 0x4000 0x0 0x0 ----- -> N/A 0x5000 0x0 0x0 ----- -> N/A 0x6000 0x0 0x0 ----- -> N/A 0x7000 0x0 0x0 ----- -> N/A 0x8000 0x0 0x0 ----- -> N/A 0x9000 0x0 0x0 ----- -> N/A 0xffff6000 0x0 0x0 ----- -> N/A 0xffff7000 0x0 0x0 ----- -> N/A 0xffff8000 0x0 0x0 ----- -> N/A 0xffff9000 0x0 0x0 ----- -> N/A 0xffffa000 0x0 0x0 ----- -> N/A 0xffffb000 0x0 0x0 ----- -> N/A 0xffffc000 0x0 0x0 ----- -> N/A 0xffffd000 0x0 0x0 ----- -> N/A 0xffffe000 0x21fd08c7 0x87f42000 VRW-- -> <MAXVA - 2 * PGSIZE>, Trapframe 0xfffff000 0x2000184b 0x80006000 VR-X- -> <MAXVA - 1 * PGSIZE>, Trampoline
Speed up system calls
这个任务要求内核把一个 usyscall 页面映射给用户空间,让 ugetpid
函数可以通过读取这个页面中的信息直接获得 pid,不经过系统调用。参考
kernel/proc.c 中对 trapframe 页面的处理方式。
首先看看 trapframe 是怎么处理的。
kernel/proc.c:fork 创建新的进程时,会先使用 allocproc
分配并初始化一个 PCB。
allocproc 会分配一个 trapframe,它是 per-process 的。
接着 allocproc 会创建并初始化用户的 page table,在 proc_pagetable
函数中。这个时候会 map trampoline / trapframe 到用户内存。前一步中
trampoline 没有用 kalloc 重新分配,因为 trampoline 是所有 process
共享的。
于是我们要做的事情就是 per process 地创建 usyscall 页面,把它放在 PCB
里,然后通过 mappages 来把它引射到用户态,共享 pid。
可以看到 memlayout.h 已经定义好了一个 usyscall 的结构,以及 usyscall
page 应该位于的用户地址(trapframe 底下一个页面):
kernel/memlayout.h 1 2 3 4 5 6 #define USYSCALL (TRAPFRAME - PGSIZE) struct usyscall { int pid; };
我们需要在 PCB 的定义中加一个指向 usyscall 页面的指针:
kernel/proc.h 1 2 3 4 5 6 7 struct proc { struct usyscall *usyscall ; };
由于 usyscall 也是 per-process 的(因为这个页面创建的目的是为了共享
per-process 的数据),所以我们需要在每个进程被 fork 出来的时候单独用
kalloc 分配一个页面:
kernel/proc.c:allocproc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static struct proc*allocproc (void ) struct proc *p ; found: p->pid = allocpid(); p->state = USED; if ((p->trapframe = (struct trapframe *)kalloc()) == 0 ){ } if ((p->usyscall = (struct usyscall *)kalloc()) == 0 ){ freeproc(p); release(&p->lock); return 0 ; } return p; }
分配完这个页面之后,要在 user page table 创建并初始化的时候把这个
page map 到 user space。这里可以在 map 完 trampoline 和 trapframe
之后添加对 usyscall 的 map,要注意如果 map 失败则要取消对前两个页面的
map。permission 设置为用户可读。
kernel/proc.c:proc_pagetable 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 pagetable_t proc_pagetable (struct proc *p) pagetable_t pagetable; pagetable = uvmcreate(); if (pagetable == 0 ) return 0 ; if (mappages(pagetable, USYSCALL, PGSIZE, (uint64)(p->usyscall), PTE_R | PTE_U) < 0 ) { uvmunmap(pagetable, TRAMPOLINE, 1 , 0 ); uvmunmap(pagetable, TRAPFRAME, 1 , 0 ); uvmfree(pagetable, 0 ); return 0 ; } return pagetable; }
这样我们就在分配并初始化 PCB 的时候分配、初始化并映射了这个 usyscall
的页面,那我们也需要在 PCB 生命周期结束的时候回收这个页面:
kernel/proc.c:freeproc 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static void freeproc (struct proc *p) if (p->trapframe) kfree((void *)p->trapframe); p->trapframe = 0 ; if (p->usyscall) kfree((void *)p->usyscall); p->usyscall = 0 ; if (p->pagetable) proc_freepagetable(p->pagetable, p->sz); p->pagetable = 0 ; }
kernel/proc.c:proc_freepagetable 1 2 3 4 5 6 7 8 void proc_freepagetable (pagetable_t pagetable, uint64 sz) uvmunmap(pagetable, TRAMPOLINE, 1 , 0 ); uvmunmap(pagetable, TRAPFRAME, 1 , 0 ); uvmunmap(pagetable, USYSCALL, 1 , 0 ); uvmfree(pagetable, sz); }
最后,我们需要在 fork 的时候把 pid 写到这个页面上:
kernel/proc.c:fork 1 2 3 4 5 6 7 8 9 10 11 12 int fork (void ) pid = np->pid; np->usyscall->pid = pid; return pid; }
这个任务还留了一个问题:
Which other xv6 system call(s) could be made faster using this shared
page? Explain how.
例如 read 函数从 pipe 读这个场景。xv6 的 pipe 是一个内核 buffer,用
ring buffer 实现。read 操作的本质对于 pipe 来说是维护
nread(读指针)的位置,并且把已读的内容通过 copyout
的方式复制到用户空间。这里就存在一个优化空间,如果可以把这个 kernel
buffer 给 map 到 user space,让用户程序可以从这个 buffer
读,并且让用户程序维护这个
nread,就可以避免一次系统调用。不过这样从一定程度上削弱了内核对这个
buffer 的控制——原来的设计只需要用户调用一个接口就可以从 pipe
中读,使用这种方法来做纯用户态的实现需要用户理解这个 ring buffer
的模型。
这里应该还有其他的例子,等刷完在回来看看。待填坑。
Print a page table
这个任务是遍历三级页表,打印出所有有效的 PTE
的信息。思路不复杂,从给出的最顶级页表开始 DFS 即可。
不过从这个任务可以帮助理解页表的结构:
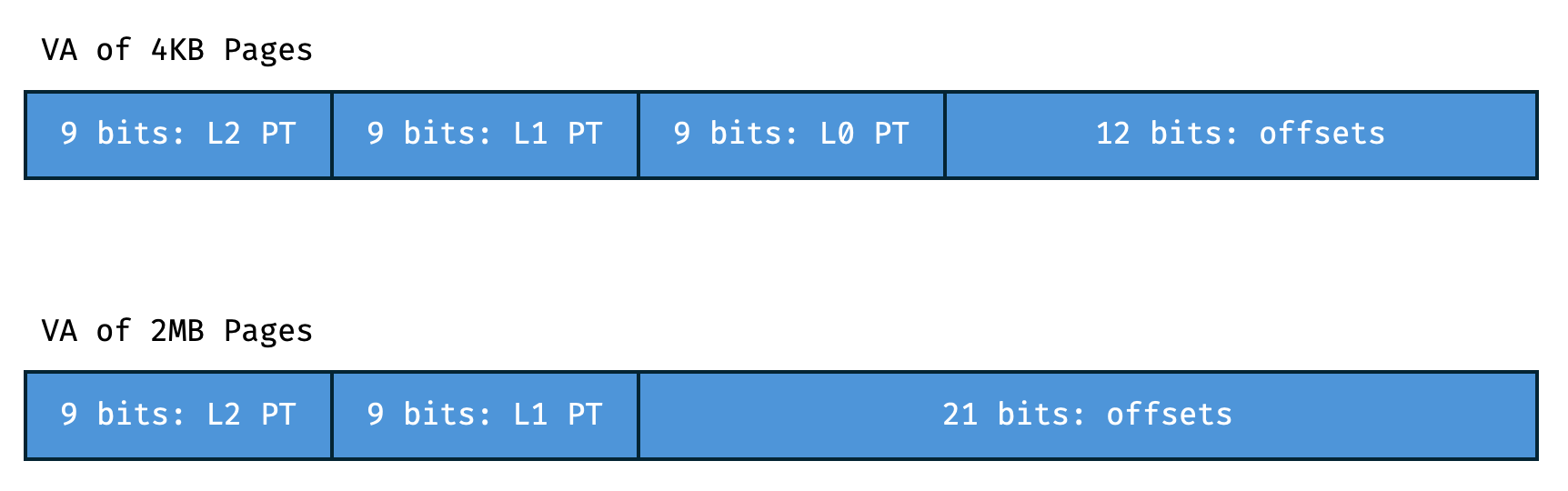
typedef uint64 *pagetable_t 从定义可以看出 pagetable_t
是一个指向 uint64 的指针类型,这里其实代表了一个长度为 \(2^9 = 512\) 的 PTE 数组。每一级页表中 PTE 所代表的区间长度是不一样的:顶级页表最大,有 \(2^9 \times 2^9 \times
2^{12}\) ;最低级的别表最小,只有 \(2^{12}\) 。
三级页表是一个三层的 512
叉树。从最终打印出来的结果可以看到用户地址空间的页表常常是稀疏的,所以多级页表可以避免页表的空间浪费。但是三级页表比一级页表多了「两跳」,这是一种用时间换空间。
PTE 的后 10 位是标志位,接着的 44 位是物理地址的页面号
PPN。所以这里的 PTE2PA 是把 pte 先右移 10 位,再左移 12 位。
从 freewalk 函数可以看出当满足
(pte & (PTE_R | PTE_W | PTE_X)) == 0 条件时,当前的 pte
指向更低一级别的页表。
kernel/vm.c:vmprint 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void vmprint_dfs (pagetable_t pagetable, uint64 va, int depth) uint64 va_step = (1UL << (9 * (3 - depth))) << 12 ; for (int i = 0 ; i < 512 ; ++i) { pte_t pte = pagetable[i]; if (!(pte & PTE_V)) { continue ; } for (int j = 0 ; j < depth; ++j) { printf (" .." ); } printf ("%p: pte %p pa %p\n" , (void *)(va + i * va_step), (void *)pte, (void *)PTE2PA(pte)); if (depth < 3 ) { vmprint_dfs((pagetable_t )PTE2PA(pte), va + i * va_step, depth + 1 ); } } } void vmprint (pagetable_t pagetable) printf ("page table %p\n" , pagetable); vmprint_dfs(pagetable, 0 , 1 ); }
For every leaf page in the vmprint output, explain what it logically
contains and what its permission bits are, and how it relates to the
output of the earlier print_pgtbl() exercise above. Figure 3.4 in the
xv6 book might be helpful, although note that the figure might have a
slightly different set of pages than the process that's being inspected
here.
这边的 7 个页面,其中 6 个可以和第一个任务中的 6
个页面对应起来,还有一个是我们在第二个任务中加入的 usyscall。
1 2 3 4 5 6 7 8 9 10 11 ..0x0000000000000000: pte 0x0000000021fc7801 pa 0x0000000087f1e000 .. ..0x0000000000000000: pte 0x0000000021fc7401 pa 0x0000000087f1d000 .. .. ..0x0000000000000000: pte 0x0000000021fc7c5b pa 0x0000000087f1f000 -> VR-XU Text .. .. ..0x0000000000001000: pte 0x0000000021fc70d7 pa 0x0000000087f1c000 -> VRW-U Data .. .. ..0x0000000000002000: pte 0x0000000021fc6c07 pa 0x0000000087f1b000 -> VRW-- Guard .. .. ..0x0000000000003000: pte 0x0000000021fc68d7 pa 0x0000000087f1a000 -> VRW-U Stack ..0x0000003fc0000000: pte 0x0000000021fc8401 pa 0x0000000087f21000 .. ..0x0000003fffe00000: pte 0x0000000021fc8001 pa 0x0000000087f20000 .. .. ..0x0000003fffffd000: pte 0x0000000021fd4c13 pa 0x0000000087f53000 -> VR--U Usyscall .. .. ..0x0000003fffffe000: pte 0x0000000021fd00c7 pa 0x0000000087f40000 -> VRW-- Trapframe .. .. ..0x0000003ffffff000: pte 0x000000002000184b pa 0x0000000080006000 -> VR-X- Trampoline
Use superpages
这个任务要修改 xv6 内核实现 2MB 的大页(superpage),目标是通过
pgtbltest.c 中的 superpg_test 测试。
这个任务还是有些难度的。
使用大页的意义
Use of superpages decreases the amount of physical memory used by the
page table, and can decrease misses in the TLB cache. For some programs
this leads to large increases in performance.
减少页表占用物理内存的大小,减少 TLB
缓存为命中次数。对于一些程序来说可以很大程度提高性能。
思路和实现
从 sbrk 入手。在内存分配的过程中,它经过了这样一条链路 sbrk -
growproc - uvmalloc,在 uvmalloc 中原来的代码按照每次分配一个 PGSIZE
来增长堆内存的大小,每个 PGSIZE 由 kalloc
分配。我们这里需要在待分配的大小大于 2MB 的时候,优先分配大页,也就是用
superalloc 代替 kalloc,我们需要加入这三个函数。
kernel/defs.h 1 2 3 void * superalloc (void ) void superfree (void *) int superpage_allocable ()
superalloc / superfree
好理解,用来分配和释放大页。superpage_allocable
可以用来判断当前是否可以分配大页,用来做异常触发的条件,这个函数是在我最后跑
usertests 的时候发现有 regression 才加上的。
接下来我们要仿照 4KB
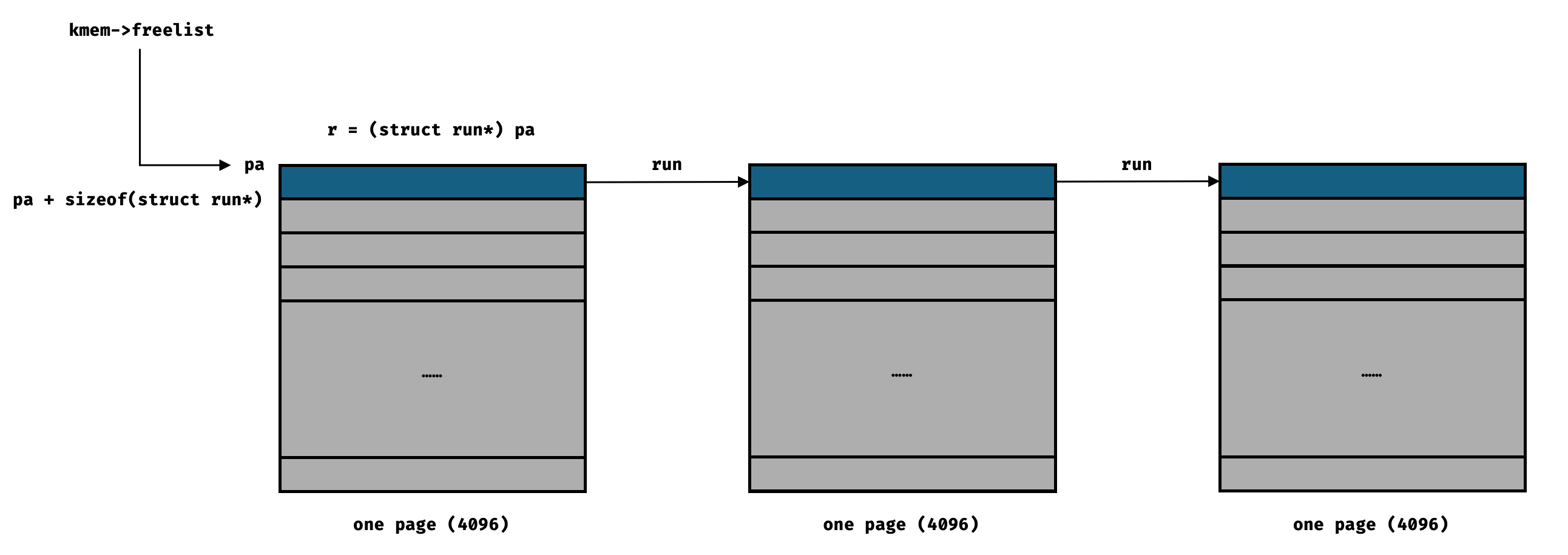
页面的分配回收方法来实现这几个函数,理解这个过程很重要。4KB
的页面采用一个链表 kmem.freelist
来维护空闲的页面,每个页面的最前端的几个字节(一个指针的大小)指向下一个空闲页,这个设计很精妙,用页面本身来存下一个页面的地址。
这些页面所对应的节点在 kinit - freerange 的时候被初始化并加入
freelist。kinit 把 kernel 之后的所有虚拟地址空间(一直到
PHYSTOP)都加入了
kmem.freelist。位了实现大页,我们希望其中的一些小页面的内存合并起来,并且合并后的大页的起始地址需要和
2MB 对齐。这个对齐是必要的,因为它保证了后 21 位是
offset。从这一点看大页是在 4KB 页面机制的基础下把 L0 的页表归入了
offset。
实现它的办法有多种。我们既可以预先分配一个 4KB / 2MB 页面在 VA
中的界限,kalloc / superalloc 分别管这两个 VA 段;也可以动态地寻找这个
2MB 的页面,让 4KB 页面和 2 MB 页面混在一起。通过阅读 pgtbltest
的代码,我们知道这里只需要我们预留 8 个 2MB(原进程
(8 * (1 << 20)) = \(4
\times 2^{21}\) = 4 * 2 MB 即 4 个大页,fork 出来的进程也有 4
个大页,共 8
个)。简单起见,我们选择前者。我的代码中定义的这个界限够分配 10
个大页。以下是 kalloc.c 中增加 / 修改的部分。
kernel/kalloc.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #define SUPERPAGES_NUM 10 #define SUPERPAGES_START (PHYSTOP - SUPERPAGES_NUM * 2 * 1024 * 1024) struct { struct spinlock lock ; struct run *freelist ; } kmem, kmem_super; void kinit () initlock(&kmem.lock, "kmem" ); freerange(end, (void *)(SUPERPAGES_START - 1 )); initlock(&kmem_super.lock, "kmem_super" ); freerange_super((void *)SUPERPAGES_START, (void *)PHYSTOP); } void freerange_super (void *pa_start, void *pa_end) char *p; p = (char *)SUPERPGROUNDUP((uint64)pa_start); for (; p + SUPERPGSIZE <= (char *)pa_end; p += SUPERPGSIZE) superfree(p); } void superfree (void *pa) struct run *r ; if (((uint64)pa % SUPERPGSIZE) != 0 || (uint64)pa < (uint64)SUPERPAGES_START || (uint64)pa >= PHYSTOP) panic("superfree" ); memset (pa, 1 , SUPERPGSIZE); r = (struct run*)pa; acquire(&kmem_super.lock); r->next = kmem_super.freelist; kmem_super.freelist = r; release(&kmem_super.lock); } void *superalloc (void ) struct run *r ; acquire(&kmem_super.lock); r = kmem_super.freelist; if (r) kmem_super.freelist = r->next; release(&kmem_super.lock); if (r) memset ((char *)r, 5 , SUPERPGSIZE); return (void *)r; } int superpage_allocable () return kmem_super.freelist != 0 ; }
uvmalloc 中使用 mappages 把 kalloc / superalloc 分配出来的页面 map
到一个可用的物理地址。这里我们可以巧用 perm
中保留的第八位来作为大页的标志,好让 mappages 知道我们需要 map 一个 4KB
页还是 2 MB 页面。
kernel/riscv.h 1 2 3 4 5 6 #define PTE_V (1L << 0) #define PTE_R (1L << 1) #define PTE_W (1L << 2) #define PTE_X (1L << 3) #define PTE_U (1L << 4) #define PTE_S (1L << 8)
我们也需要让 walk 知道。walk 有两个作用:一个是页面还没有 map
的时候找到一个 pte 来 map 这个页面,如果页表不存在则创建一个 4KB
的页面作为一级页表索引;另一个作用是在 VA 所对应的页面和 PTE
都是有效的情况下,可以手动翻译一个 VA。mappages 使用了前者。所以我们要让
walk 知道,如果是 2MB 页面的话,不要在 L0 级停,要在 L1 级停,因为对于
2MB 页面来说,后 21 位全是 offset。
这里我们用 alloc 参数为 2 来代表分配
2MB,当然这有些投机取巧,不过足以区分。
kernel/vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 pte_t *walk (pagetable_t pagetable, uint64 va, int alloc) if (va >= MAXVA) panic("walk" ); for (int level = 2 ; level > 0 ; level--) { pte_t *pte = &pagetable[PX(level, va)]; if (*pte & PTE_V) { pagetable = (pagetable_t )PTE2PA(*pte); #ifdef LAB_PGTBL if (PTE_LEAF(*pte)) { return pte; } #endif } else { if (!alloc || (pagetable = (pde_t *)kalloc()) == 0 ) return 0 ; memset (pagetable, 0 , PGSIZE); *pte = PA2PTE(pagetable) | PTE_V; } if (alloc == 2 && level == 2 ) { pagetable[PX(1 , va)] |= (PTE_R); return &pagetable[PX(1 , va)]; } } return &pagetable[PX(0 , va)]; }
kernel/vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int mappages (pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm) uint64 a, last; pte_t *pte; uint64 pg_size = (perm & PTE_S) ? SUPERPGSIZE : PGSIZE; if ((va % pg_size) != 0 ) panic("mappages: va not aligned" ); if ((size % pg_size) != 0 ) panic("mappages: size not aligned" ); if (size == 0 ) panic("mappages: size" ); a = va; last = va + size - pg_size; for (;;){ if ((pte = walk(pagetable, a, (perm & PTE_S) ? 2 : 1 )) == 0 ) return -1 ; if (*pte & PTE_V) panic("mappages: remap" ); *pte = PA2PTE(pa) | perm | PTE_V; if (a == last) break ; a += pg_size; pa += pg_size; } return 0 ; }
实现了这些依赖后,我们就可以实现 uvmalloc 了。位了让大页和 2MB
对齐,我们需要把当前 proc->sz 到它 roundup 到第一个 2MB
对齐位置之间的内存用 4KB
的页面分配掉。起初我尝试不分配这部分,但是在内存释放的时候出现了问题,xv6
设计的内存释放假设堆内存是连续的(非常 make sense 的假设),这部分参考
uvmfree - uvmunmap。接下来遵循待分配大于等于 2MB 时优先分配 2MB
页面的规则。这里一定要模仿原来 4KB
页面的写法,如果页面分配失败或者 map 失败,需要进行回滚,否则会在
usertests 中测出 regression。
kernel/vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 uint64 uvmalloc (pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm) char *mem; uint64 a; int sz; uint64 oldsz_bk = oldsz; if (newsz < oldsz) { return oldsz; } oldsz = PGROUNDUP(oldsz); if (newsz >= oldsz + SUPERPGSIZE) { uint64 s_oldsz = SUPERPGROUNDUP(oldsz); for (a = oldsz; a < s_oldsz; a += PGSIZE) { sz = PGSIZE; mem = kalloc(); if (mem == 0 ) { uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } memset (mem, 0 , sz); if (mappages(pagetable, a, sz, (uint64)mem, PTE_R | PTE_U | xperm) != 0 ) { kfree(mem); uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } } oldsz = s_oldsz; } for (a = oldsz; a < newsz; a += sz){ if (newsz >= oldsz + SUPERPGSIZE && superpage_allocable()) { sz = SUPERPGSIZE; mem = superalloc(); if (mem == 0 ) { uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } memset (mem, 0 , sz); if (mappages(pagetable, a, sz, (uint64)mem, PTE_S | PTE_R | PTE_U | xperm) != 0 ) { superfree(mem); uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } } else { sz = PGSIZE; mem = kalloc(); if (mem == 0 ){ uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } #ifndef LAB_SYSCALL memset (mem, 0 , sz); #endif if (mappages(pagetable, a, sz, (uint64)mem, PTE_R|PTE_U|xperm) != 0 ){ kfree(mem); uvmdealloc(pagetable, a, oldsz_bk); return 0 ; } } } return newsz; }
下面我们要实现 fork 的时候 copy 大页的功能。我们可以看出 fork 使用
uvmcopy 从父进程复制虚拟地址空间。由于我们使用了 PTE_S
标记大页,我们只需要在 uvmcopy 中通过这个标记决定使用 kalloc 还是
superalloc 分配即可。
kernel/vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 int uvmcopy (pagetable_t old, pagetable_t new , uint64 sz) pte_t *pte; uint64 pa, i; uint flags; char *mem; int szinc; uint64 pages_alloc = 0 ; for (i = 0 ; i < sz; i += szinc){ if ((pte = walk(old, i, 0 )) == 0 ) panic("uvmcopy: pte should exist" ); if ((*pte & PTE_V) == 0 ) panic("uvmcopy: page not present" ); pa = PTE2PA(*pte); flags = PTE_FLAGS(*pte); if (flags & PTE_S) { if ((mem = superalloc()) == 0 ) goto err; memmove(mem, (char *)pa, SUPERPGSIZE); if (mappages(new , i, SUPERPGSIZE, (uint64)mem, flags) != 0 ) { superfree(mem); goto err; } } else { if ((mem = kalloc()) == 0 ) goto err; memmove(mem, (char *)pa, PGSIZE); if (mappages(new , i, PGSIZE, (uint64)mem, flags) != 0 ){ kfree(mem); goto err; } } ++pages_alloc; szinc = (flags & PTE_S) ? SUPERPGSIZE : PGSIZE; } return 0 ; err: uvmunmap(new , 0 , pages_alloc, 1 ); return -1 ; }
最后我们要实现回收进程的时候释放页面。释放页面的操作在 wait
函数中,链路是 wait - freeproc - proc_freepagetable - uvmfree -
uvmunmap。这里我们需要改 uvmunmap。
我们看到 uvmunmap 的参数是
p->sz / PGSIZE,可能会觉得这里不太好处理,因为它把大页也按照小页面算,我最初考虑是不是要单独写函数释放大页,甚至希望把前面的设计推倒。但是这里如果只是为了过测试,可以再做个投机取巧的设计:在
uvmunmap 中还是通过 PTE_S
来决定循环的步长,每遇到一个大页相当于跳 512
个小页。在真实的设计中,需要考虑更加优雅的方法。
kernel/vm.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void uvmunmap (pagetable_t pagetable, uint64 va, uint64 npages, int do_free) uint64 a; pte_t *pte; if ((va % PGSIZE) != 0 ) panic("uvmunmap: not aligned" ); a = va; for (uint64 i = 0 ; i < npages; ) { if ((pte = walk(pagetable, a, 0 )) == 0 ) panic("uvmunmap: walk" ); if ((*pte & PTE_V) == 0 ) { printf ("va=%ld pte=%ld\n" , a, *pte); panic("uvmunmap: not mapped" ); } if (PTE_FLAGS(*pte) == PTE_V) panic("uvmunmap: not a leaf" ); int super = (*pte & PTE_S); if (do_free){ uint64 pa = PTE2PA(*pte); if (super) { superfree((void *)pa); } else { kfree((void *)pa); } } a += super ? SUPERPGSIZE : PGSIZE; *pte = 0 ; i += super ? 512 : 1 ; } return ; }
至此,我们就实现了第四个任务所有的功能。
实验结果
搞定!