6.1810 Lab - System Calls
实验指导:Lab - System Calls
实验任务
Using gdb
Looking at the backtrace output, which function called syscall?
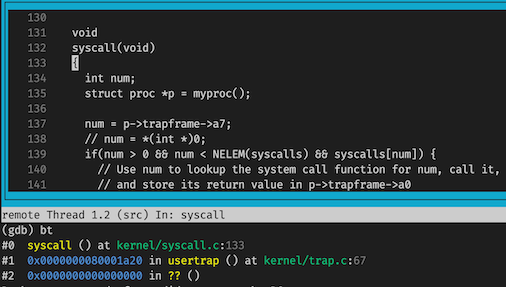
bt 之后可以看出是 usertrap()。
What is the value of p->trapframe->a7 and what does that value represent?
- 在
initCode.S中可以看到li a7, SYS_exec。a7寄存器中存放的是 system call 的 ID。 - 在执行完
*p = myproc()之后p /x $a7打印出来的值是 0x7,查看系统调用表,它代表SYS_fstat。
1 | static uint64 (*syscalls[])(void) = { |
What was the previous mode that the CPU was in?
RISC-V privileged instructions 表示 「When a trap is taken, SPP is
set to 0 if the trap originated from user mode, or 1
otherwise」。于是我们要看 SPP 位,SPP 位是 sstatus
寄存器的第八位。p /x $sstatus1 的结果是
0x20000022,第八个比特位是 0,于是可以确认是 user
mode。
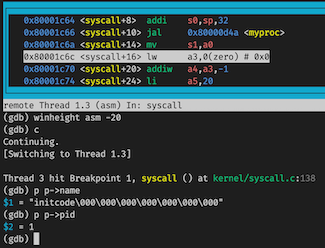
Write down the assembly instruction the kernel is panicing at. Which register corresponds to the variable num?
在 kernel.asm
中可以看到是这条:80001c6c: 00002683 lw a3,0(zero) # 0 <_entry-0x80000000>。指令是
lw,寄存器是 a3。
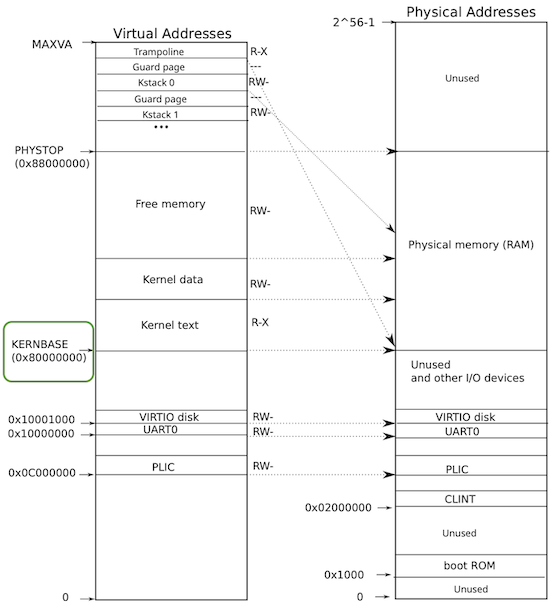
Why does the kernel crash? Hint: look at figure 3-3 in the text; is address 0 mapped in the kernel address space? Is that confirmed by the value in scause above?
VMA 0x0 (PMA 0x80000000) 在内核空间。scause = 0xd 是 Load page fault。应该是因为在用户态不能 dereference 内核空间的地址。
What is the name of the process that was running when the kernel paniced? What is its process id (pid)?
PID 是 0x1,进程名是 initcode。
System call tracing
这个 task 要求实现一个 syscall 来 trace 给定的 syscall。例如
trace 32 grep hello README 可以打印出
grep hello README 的进程和它所有的子进程的
read 调用,32 是 read
的掩码。这里的掩码(mask)可以用一个 32 位的数表示,每一位代表一个
syscall。xv6 总共的 syscall 的数量只有不到 32 个。
整理一下 xv6 syscall 的流程:
- 用户程序调用
user/user.h中的 syscall wrapper。这些 wrapper 的实现代码在user/usys.S中,这个汇编代码由user/usys.pl生成。 user/usys.pl生成代码用ecall指令系统调用。$stvec寄存器中保存着响应代码的地址,当ecall被触发后跳转到$stvec指向的代码,即tampoline.S。这一步是由硬件来完成的。在真正跳转到$stvec之前硬件会自动保存一些硬件上下文,例如$sepc/$sstatus/$scause。- trampoline 的代码会保存用户上下文,然后跳转到
kernel/trap.c:usertrap。 kernel/trap.c:usertrap调用kernel/syscall.c:syscall函数。这也验证了我们在第一个任务中看到的。kernel/syscall.c:syscall通过查表来确定和调用系统调用函数。kernel/syscall.c:syscall使用kernel/syscall.c:usertrapret结束调用,跳转到 trampoline 中的userret。userret恢复用户状态,调用sret恢复硬件上下文($sepc/$sstatus/$scause)并跳转到用户代码。
1 | user/user.h:syscall_wrapper_func |
所以,要给 xv6 加一个 trace 的 system call 需要首先在
user/user.h 中加入一个 wrapper 函数声明:
1 | int trace(int); |
接着在 user/usys.pl
中加入一个入口点,让构建程序可以生成这个 wrapper 函数的定义:
1 | entry("trace"); |
编译之后可以看到 user/usys.S 中生成了函数的定义:
1 | trace: |
对于 trampoline 和 usertrap 我们无需修改,下一步我们考虑让
kernel/syscall.c 支持 SYS_trace。首先在
kernel/syscall.h 中定义 SYS_trace:
1 |
然后在系统调用表中加入对这个函数的支持:
1 | extern uint64 sys_trace(void); |
下面来实现这个 syscall 的功能。这个 syscall 需要把 mask 放入 proc 结构中,好让其他 syscall 发生的时候查询 proc 结构中的 mask,来决定是否要 log 这个 syscall。
1 | struct proc { |
1 | uint64 |
接下来考虑 fork 的情况,让子进程也支持 trace 给定的 syscall,于是我们要在 fork 的时候把 mask 复制给子进程的 proc 结构。
1 | int |
最后在 kernel/syscall.c:syscall 中根据条件来打印
trace:
1 | static char* syscalls_name[] = { |
Attack xv6
xv6 kernel 的 kalloc / kfree 用一个链表管理页面的分配和回收。如果 kfree 不清空页面的数据,在这个页面下一次被 kalloc 出去的时候,当前拥有这个页面的人就可以读到上一个人写入这个页面的数据。这个题让我们基于这样一个原理,来实现 attack,窃取上一个用户的 secret。
这个题很有意思。我最初刷 syscall 实验的时候这个题卡住了,我是把 6.1810 所有 9 个实验全都刷完之后再回过头来看这个实验。
kalloc / kfree 遵循 FILO 的原则,也就意味着 secret 的第 10 个 page 在 attack 里面会是另一个 index。我一开始觉得这个 page 的 index 应该是固定的,我十分执着于找到这个 index。我在分别运行 secret 和 attack 的时候其实找到了这个 index,但是发现它并不适用于 attacktest:因为 attacktest 这个程序 fork 了两次,并非分别执行 secret 和 attack,「谁能拿到这个 secret 页面」这件事情就变得更加复杂一些。
我转而开始研究 attacktest 这个程序。通过打表的方法,我发现其实在 attacktest 这个程序里这个 page 的 index 其实也是固定的(只是和分别执行两个程序不太一样),并且我还搞到了这个 index,但是我觉得我需要理解为什么是这个 index。这就涉及到要分析每个 user program 分配 page 的行为,比如说我们知道有一些页面会被 fork 的时候 copy 到新的进程(比如 stack / heap / trapframe 等等)涉及新的 kalloc,有的不涉及 kalloc(比如 trampoline),进程结束的时候会有 kfree 的动作。于是我的思路变成了一层一层地分析每个 page 是什么时候被 kalloc / kfree 的,在纸上模拟出来。这条路是理论可行的,不过有些烧脑子。尝试梳理这个过程,未果,经常就是把自己绕进去了。
其实在此之前我还关注到了 secret 程序在打印真正的 secret 之前,还打印了“my very very very secret pw is:”,这个就在 page 开头。于是我就找哪个 page 开头是这样的字符串,结果还是没找着,当时我就纳了闷儿了。想了很久,这条路也没走通,就暂时放弃开始做后面的 labs 了。
时隔一阵子,我做完了 mmap,再回来看这个题,又开始往这两个方向尝试。可能是对 kernel 的 code 更熟悉了,这次我也想了很久,但是最终意识到 kfree 把一个 page 归还到链表上的时候,一个 page 的前 8 个字节是会被改掉的!(因为要作为 freelist 的指针)恍然大悟。这是这个题最坑的地方。这里需要理解 kalloc.c 中 kalloc / kfree 的原理,这个在 page table 实验的博文中我贴了个图。(更详细的内容在 6.1810 Lab - Page Tables)
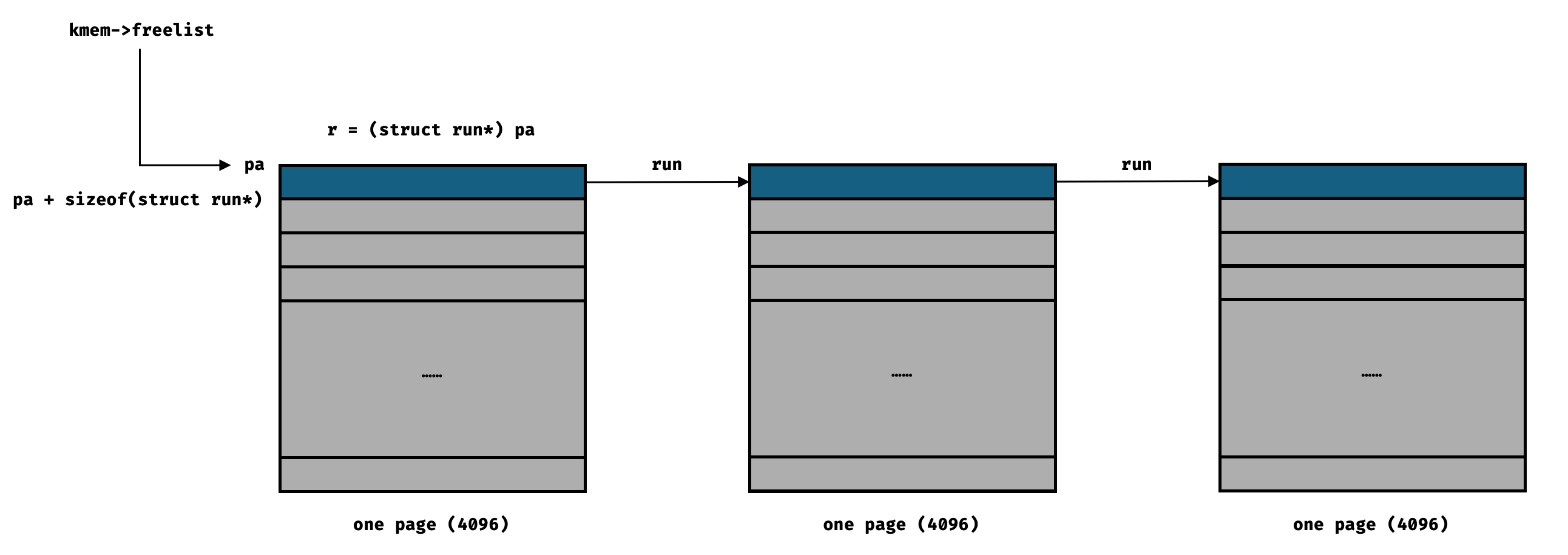
于是只要从第 8 位之后开始匹配就行了。
1 |
|
实验结果