实现带 Lexer 和 Parser 的算术解释器
网络编程老师扔了一道题,要我们写个带 Lexer 和 Parser 的算术解释器,实现变量和赋值的功能。
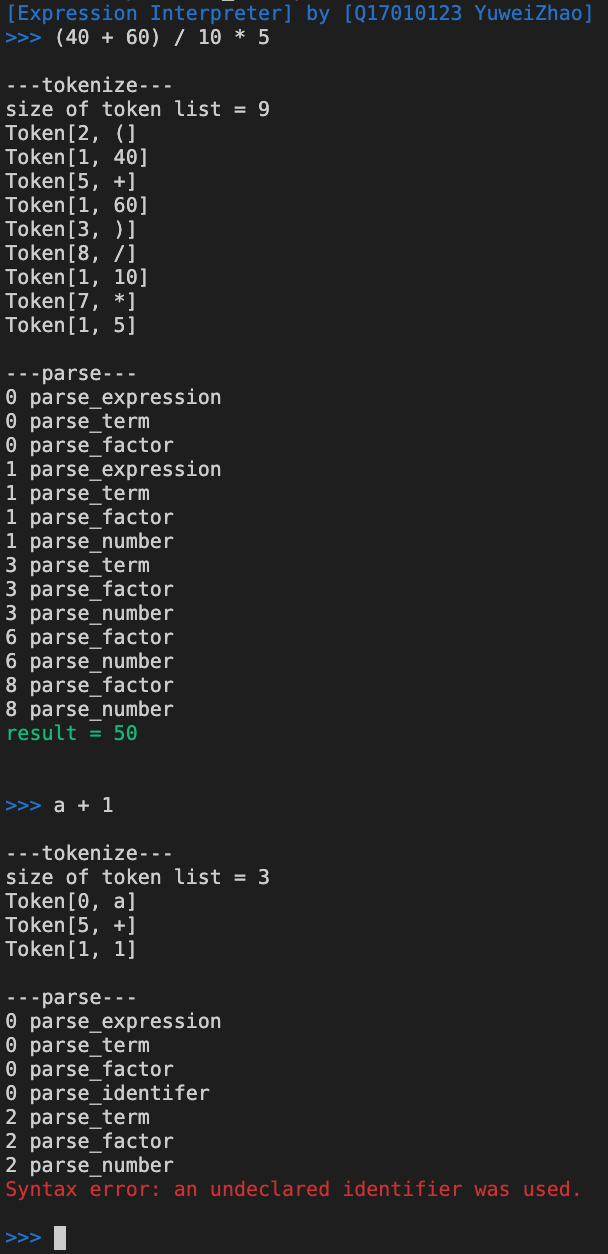
花了四天的时间,看了很多集哈工大的编译原理的MOOC(讲得还不错哦),加上写代码调BUG,基本完成了。效果大概是这样的:
写篇博文来记录一下被迫营业的心路历程。
项目代码 github: zhaoyw1999/arithmetic-interpreter 。
首先我们要知道写一个解释器的大致思路是对输入的代码做词法分析和语法分析,对应的是Lexer模块和Parser模块。
在Lexer部分,我们需要把一串长长的字符串分成一个个Token,作为下面Parser分析的最小单位。这个解释器语法所需要的Token一共有9种,分别是加减乘除、赋值、变量名、数字和左右括号,可以用枚举类型TokenType表示(在这里我还加了一个结束符END_FLAG,但是后来没有用到),这里是代码。
1 | enum TokenType { |
对于每一个Token,我们需要记录下这个Token的类型和它的字面量,其实最重要的是数字和变量名的字面量,因为我们在后面计算的时候,会后序遍历语法树,就需要用到叶子结点的字面量。在设计Token类型的时候,设计一个to_string方法,后续输出Token。
1 | struct Token { |
下面我们需要设计一个分词器,输入一个字符串,输出一个Token流。在设计Token流的时候,我们可以使用vector或者deque。这一点是我在整个解释器实现的差不多的时候才想到的,一开始设计的时候用了vector,为什么后来想到deque呢——因为在后续写Parser的过程中,是从左到右推导的,正好deque可以模拟出每次从流中取一个元素,不用自己设计一个下标计数器。
在分词器的设计上,有两种方法。一种是直接分词,适用于Token类型比较少、形式比较简单的情况;一种是设计状态机分词,适用于Token种类多、形式复杂的情况。这里我们使用前一种方法。
分词器的设计如下。
1 | using VectorStream = vector <Token>; |
因为我原本是基于vector设计的,在使用待分词的字符串初始化TokenStream之后,调用它的tokenize方法实现分词,装入一个VectorStream中,再调用用get_tokenized_vector就可以获得这个分词之后的结果。
下面到了Parser的部分。我们得到了Token的序列之后,要把Token的序列解析成一棵语法树。我们首先要列出表达式的巴斯科范式:
\[ \begin{aligned} e &: {\rm expression} \\\ t &: {\rm term} \\\ f &: {\rm factor} \\\ e & \rightarrow e + t | e - t | t \\\ t & \rightarrow t * f | t / f | f \\\ f & \rightarrow x | (e) \\\ x & \rightarrow {\rm number} | {\rm id} \\\ \end{aligned} \]
消除左递归之后:
\[ \begin{aligned} e & \rightarrow t | t e' \\\ e' & \rightarrow + t e' | - t e' | \epsilon \\\ t & \rightarrow f | f t' \\\ t' & \rightarrow * f t' | / f t' | \epsilon \\\ f & \rightarrow x | (e) \\\ x & \rightarrow {\rm number} | {\rm id} \\\ \end{aligned} \]
对于变量赋值的功能,我们可以用\({\rm id} = e\)来表示,在解析的时候,先取掉\({\rm id}=\),解析右边的\(e\),再把变量名到值的映射存在一个map里即可。这样可以直接将赋值语句的解析转到前面我们推导的表达式解析。
我们需要建立一棵语法树,我们刚刚的所有运算均为二元运算,所以语法树就表现为一个二叉树,括号不建入语法树内,那么我们建立的语法树一定只有出度为0和出度为2的节点。这是节点的设计。
1 | struct SyntaxTreeNode { |
在计算表达式的值的时候我后序遍历这颗二叉树即可。这里是Parser类的设计,其中中序遍历和先序遍历是用来调试使用的,其实应该标记为private。
1 | using std::map; |
要注意的是我们每次运行这个程序都只建立了一个Parser的实例,每次执行calculate的时候都需要先晴空万里语法树、再执行parse,但是variable_map是不需要每次清空的,因为后续的表达式可能会查询变量的值。
除了这些主要的模块之外,还需要设计一些异常处理,用来处理例如括号不匹配、使用了未定义的变量之类的异常状况。
回过头来看这四天写的代码,我觉得在设计字面值到Integer转换的时候还可以改进,因为一个好的设计,可以吧目前的Integer换成BigInteger之后依然不需要修改原来的模块。正好最近在学习Design Pattern,讲到了设计软件要应对变化,找到变与不变的分界点,这一点需要在实践中慢慢感悟。当这个语言系统变得更加复杂之后,在做词法分析的时候我们就需要用到状态机,语法分析的时候我们要考虑到底使用什么样的分析方法,希望在这学期学完编译原理之后能写出一个更复杂的解释器。